viewof input_matrix = Inputs.textarea({
label: "Input Matrix (3x3 or 4x4, space-separated)",
value: "1 0 1\n0 1 0\n1 0 1",
rows: 4
});
viewof kernel_matrix = Inputs.textarea({
label: "Kernel Matrix (2x2 or 3x3, space-separated)",
value: "1 0\n0 1",
rows: 3
});
viewof stride_val = Inputs.range([1, 2], {value: 1, step: 1, label: "Stride"});Machine Learning
CNN Model Zoo
Convolutional Neural Networks (CNNs) in ECE
Welcome to the fascinating world of Convolutional Neural Networks!
Today, we’ll dive into advanced CNN architectures commonly used in ECE for tasks like:
- Image/Video Processing: Object detection, facial recognition
- Signal Processing: Anomaly detection, medical imaging
- Robotics & Autonomous Systems: Perception, navigation

VGG16 / VGG19
Developed by the Visual Geometry Group at Oxford, known for its simplicity and uniformity.
- Architecture: Stacks 3x3 convolutional layers with 2x2 max-pooling layers.
- VGG16 has 16 layers, VGG19 has 19 layers (counted as weight layers).
- Key Idea: Proved that very deep networks with small filters (3x3) could achieve state-of-the-art performance.
- Parameters: Very high (VGG16 ~138M, VGG19 ~143M).
- Downside: Computationally expensive and memory-intensive.

ResNet (Residual Network)
Introduced by Microsoft Research, solving the vanishing gradient problem in very deep networks.
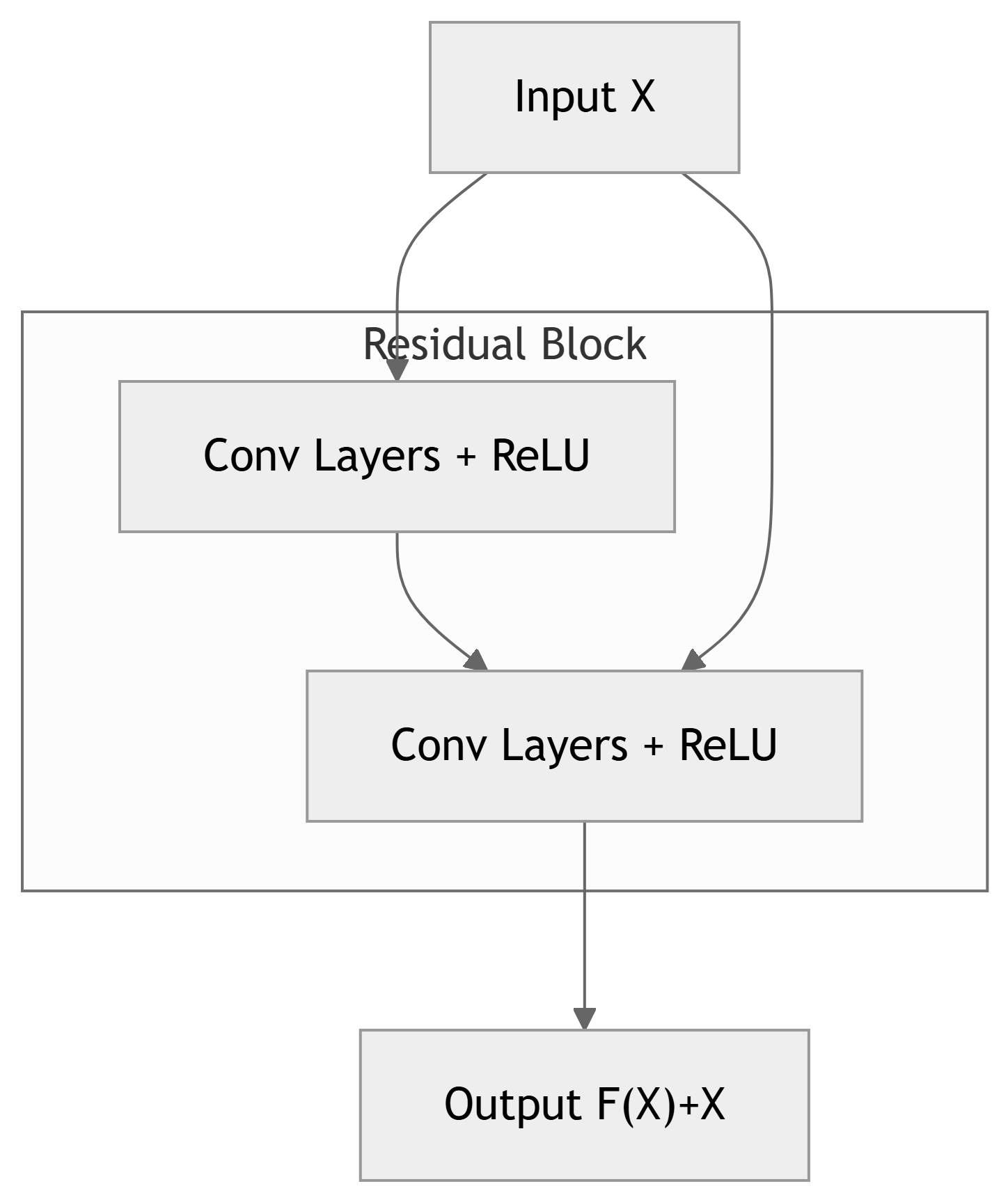
- Architecture: Features “skip connections” or “residual blocks”.
- Allows gradients to flow directly through the network.
- Enables training networks with hundreds or even thousands of layers (e.g., ResNet-50, ResNet-101, ResNet-152).
- Key Idea: Instead of learning direct mappings, layers learn residual mappings.
- \(H(x) = F(x) + x\), where \(F(x)\) is the residual function.
- Parameters: ResNet-50 ~25M parameters. Much more efficient than VGG.
ResNet (Residual Network)

ResNet (Residual Network)

Inception (GoogLeNet)
Developed by Google, emphasizing efficiency and “computational budget.”
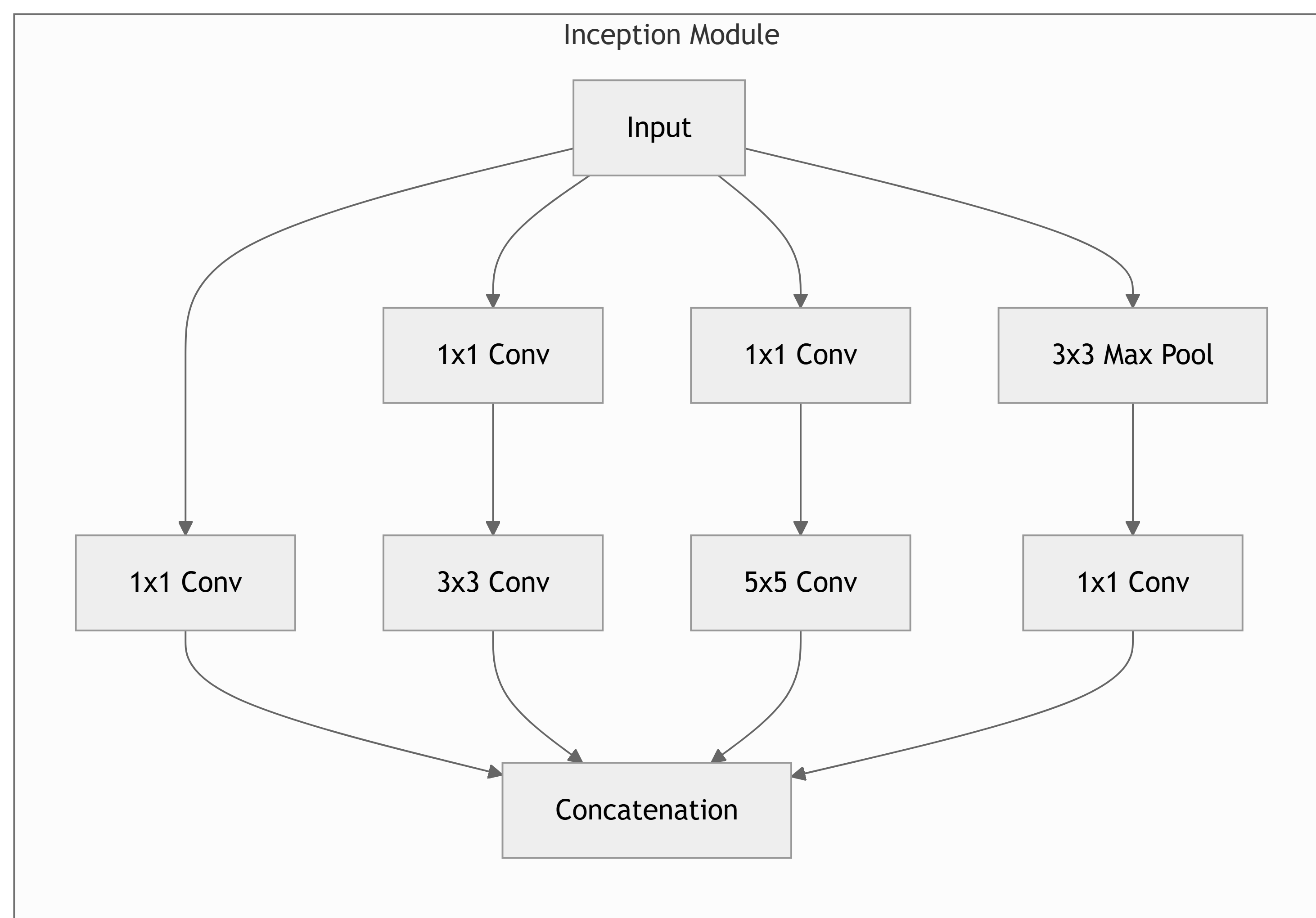
- Architecture: Uses Inception Modules (or blocks) that perform multiple parallel convolutions with different kernel sizes (1x1, 3x3, 5x5) and pooling.
- 1x1 convolutions (bottleneck layers) are used to reduce dimensionality before larger convolutions, saving computation.
- Key Idea: Allow the network to learn multiple feature representations at once, then concatenate them. Optimizes “width” and “depth” simultaneously.
- Parameters: Very low for its accuracy (GoogLeNet ~5M parameters).
- Highly efficient for deployment in real-time ECE systems.
Inception (GoogLeNet)

Inception (GoogLeNet)

Xception (Extreme Inception)
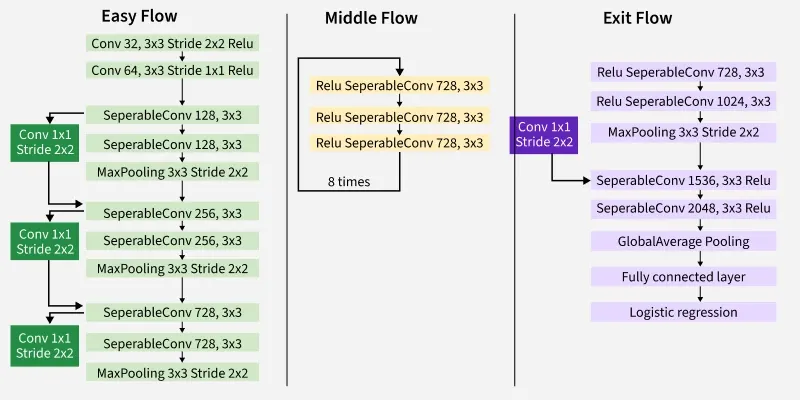
Proposed by Google, building on the Inception idea by replacing standard convolutions with depthwise separable convolutions.
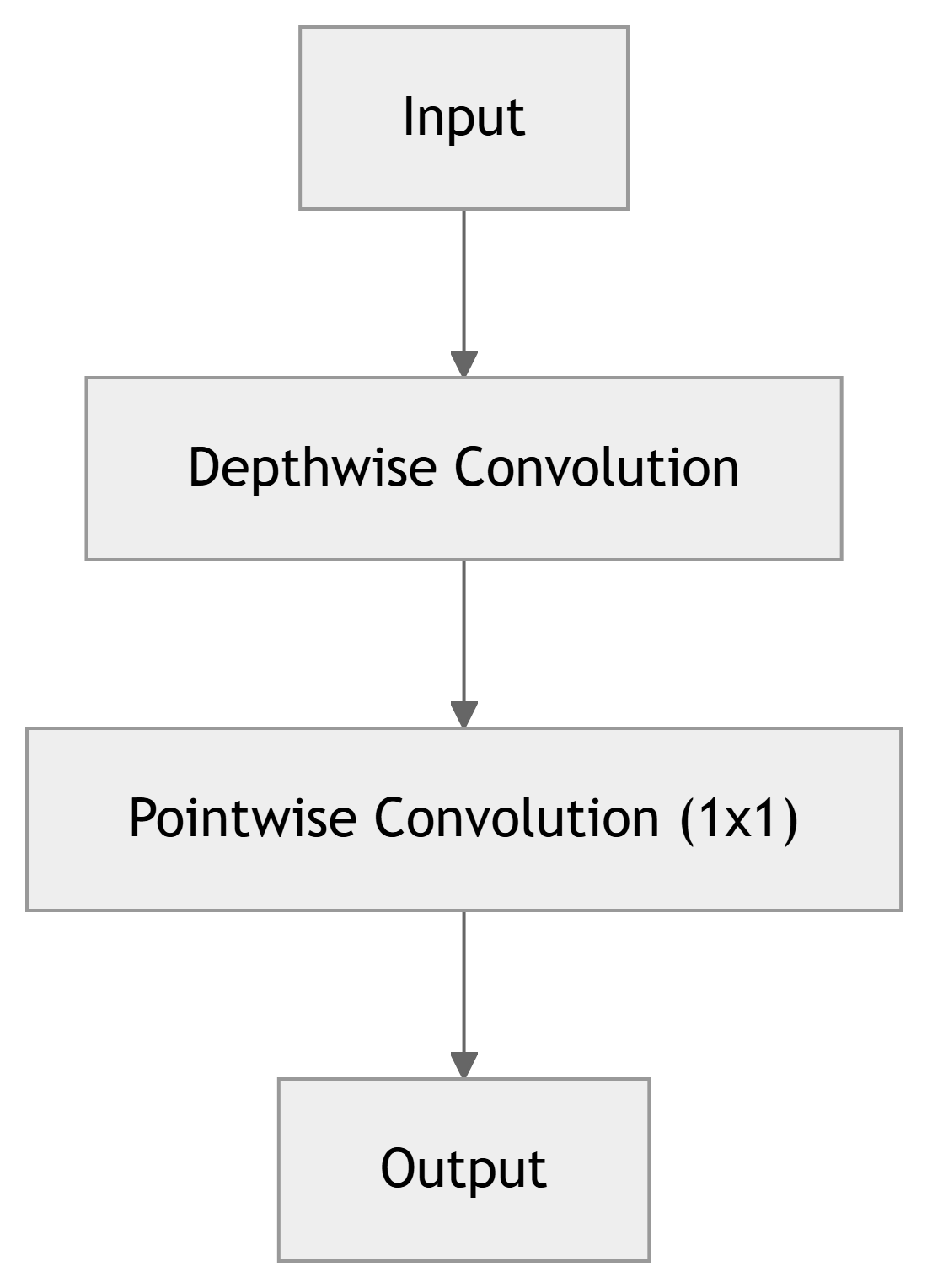
- Architecture: Inception modules are replaced with depthwise separable convolutions.
- Depthwise Conv: Applies a single filter to each input channel independently. For example, if an image has three color channels (red, green, and blue), a separate filter is applied to each color channel.
- Pointwise Conv: A 1x1 convolution projects the output of the depthwise operation into a new channel space. This is a 1×1 filter that combines the output of the depthwise convolution into a single feature map.
- Key Idea: Separating spatial and channel-wise correlations.
- More efficient parameter usage and computation than traditional convolutions.
- Parameters: Xception ~22.9M parameters.
- Achieves comparable or better accuracy than Inception with fewer parameters and FLOPs.
Xception (Extreme Inception)
Xception
MobileNet (V1, V2, V3)
Designed by Google specifically for mobile and embedded vision applications.
- Architecture: Primarily uses depthwise separable convolutions, similar to Xception.
- MobileNetV2 introduces “Inverted Residuals” and linear bottlenecks to improve efficiency and avoid information loss.
- MobileNetV3 further optimizes through NAS (Neural Architecture Search) and new activation functions.
- Key Idea: Achieve high accuracy with extremely low latency and small model size.
- Parameters: MobileNetV1 ~4.2M, MobileNetV2 ~3.5M.
- Crucial for: Real-time processing on edge devices, a core ECE application area.
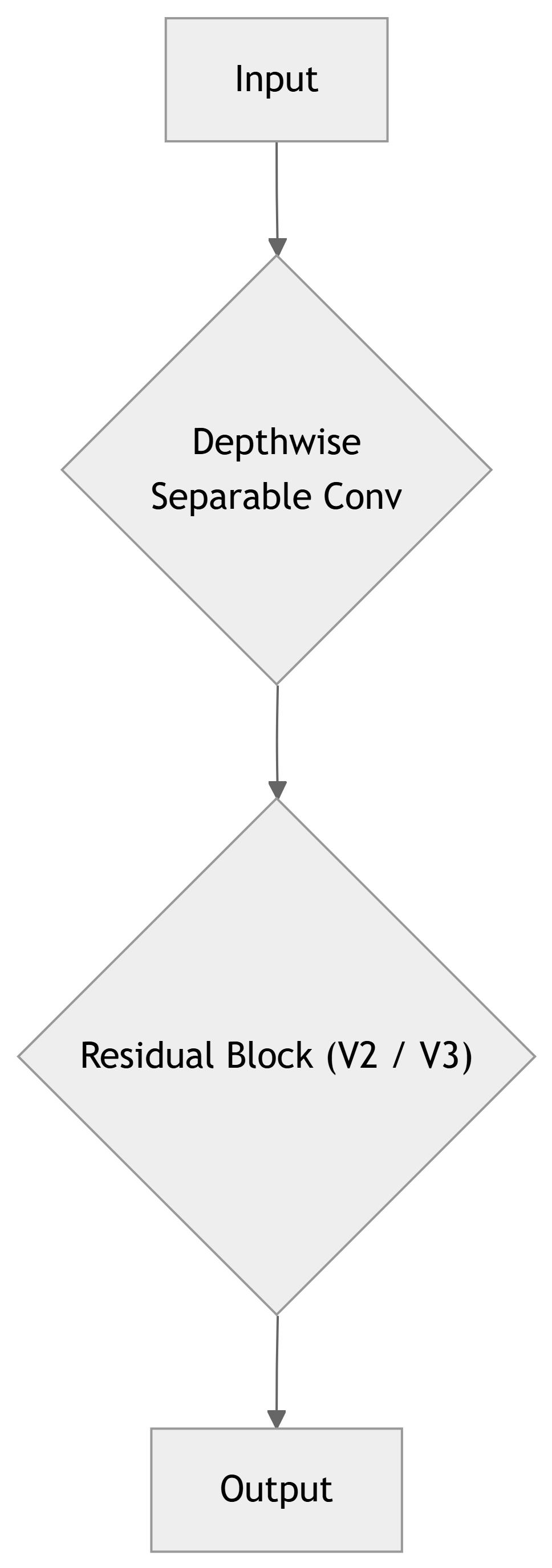
MobileNet (V1, V2, V3)

MobileNet
EfficientNet (B0 to B7)
Developed by Google, achieving state-of-the-art accuracy with significantly fewer parameters and FLOPs than previous models.
- Architecture: Uses a compound scaling method to uniformly scale width, depth, and resolution of the network.
- Scales up from a baseline model (EfficientNet-B0) to larger versions (B1-B7).
- Key Idea: It found a “recipe” for scaling CNNs more efficiently than arbitrary scaling, leading to better accuracy and efficiency trade-offs.
- Parameters: EfficientNet-B0 has ~5.3M parameters, B7 ~66M.
- Outperforms ResNets and Inception variants with orders of magnitude fewer parameters and FLOPs.
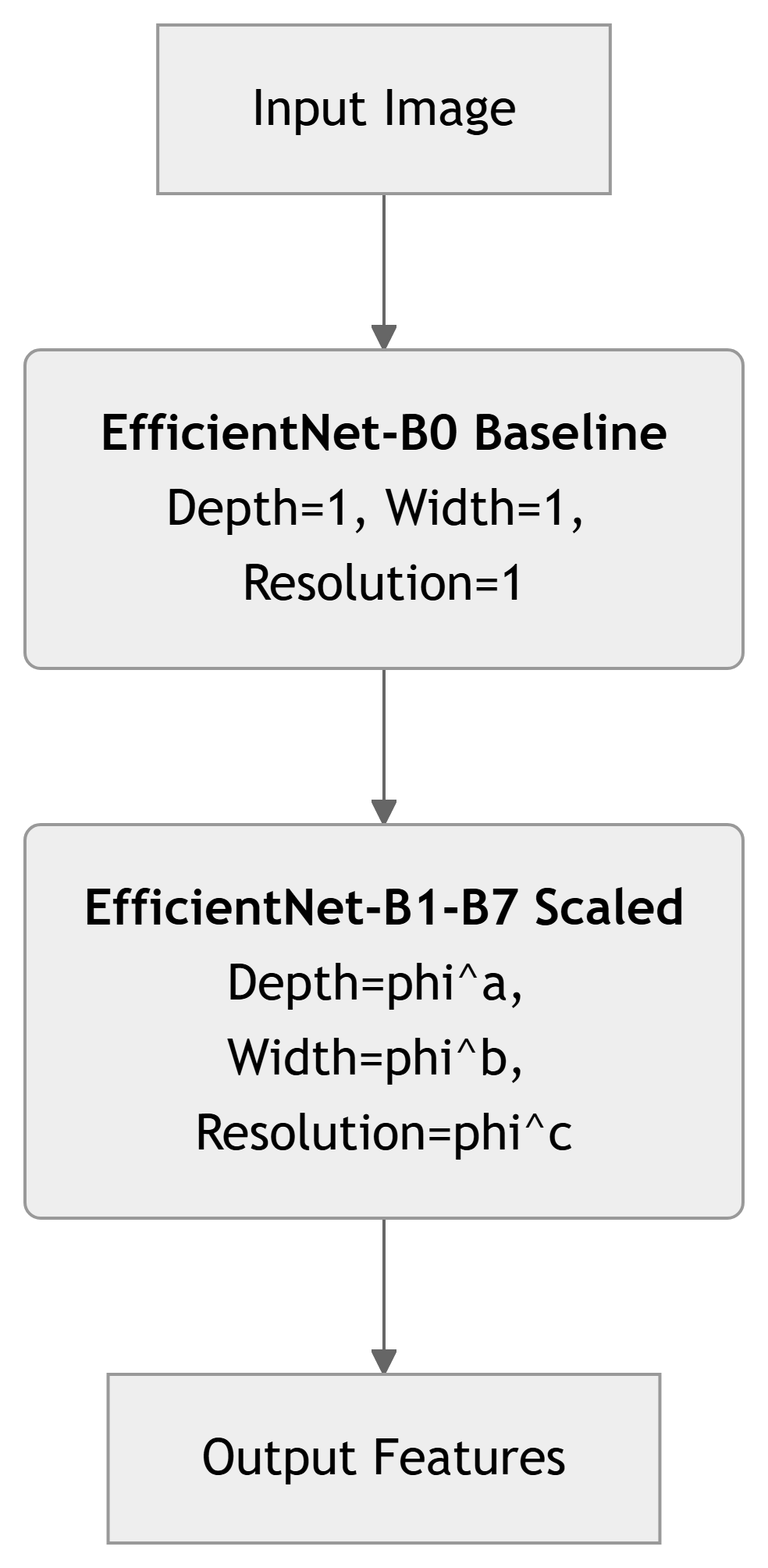
EfficientNet (B0 to B7)

EfficientNet