Machine Learning
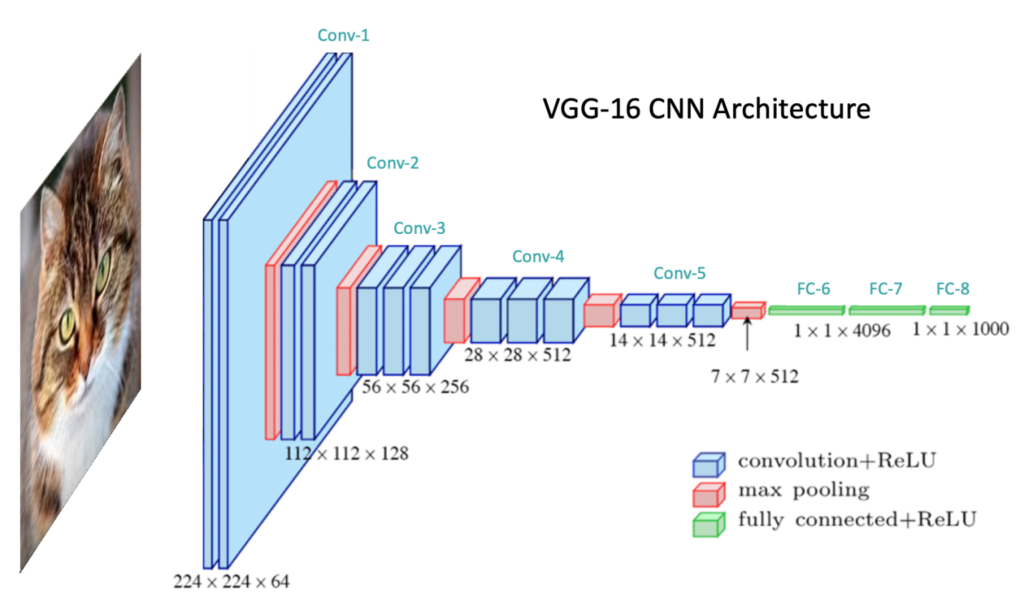
CNN
VGG-16 CNN
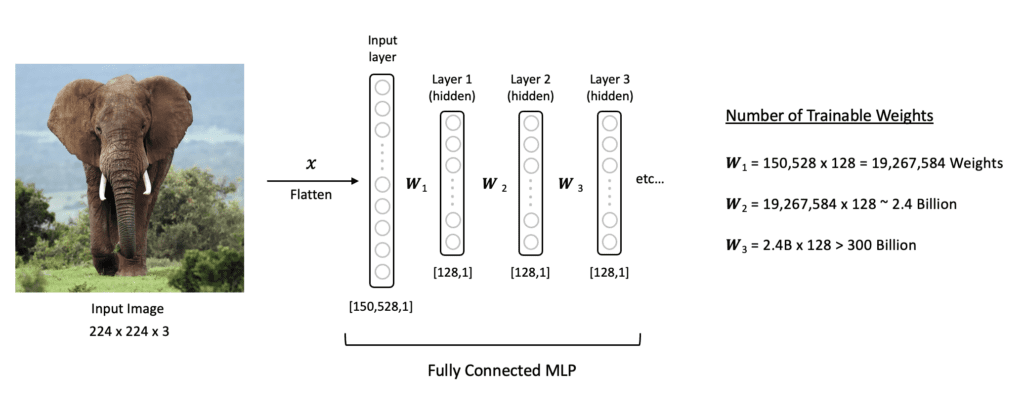
Motivation: Limitations of MLPs for Image Data
Traditional Fully Connected Networks (MLPs) struggle with image data.
1. Not Translation Invariant
- Main content shifted = different network output.
- Requires training on all possible shifts, which is inefficient.
Caution
MLPs treat each pixel as an independent feature. Spatial relationships are lost if features move.
2. Prone to Overfitting (Parameter Explosion)
- Each input pixel connects to every neuron in the next layer.
- Example: 224x224x3 color image \(\rightarrow\) 150,528 input neurons.
- With just three modest hidden layers, parameters can exceed 300 Billion!
Tip
Large number of parameters makes training difficult and increases overfitting risk.
![]()
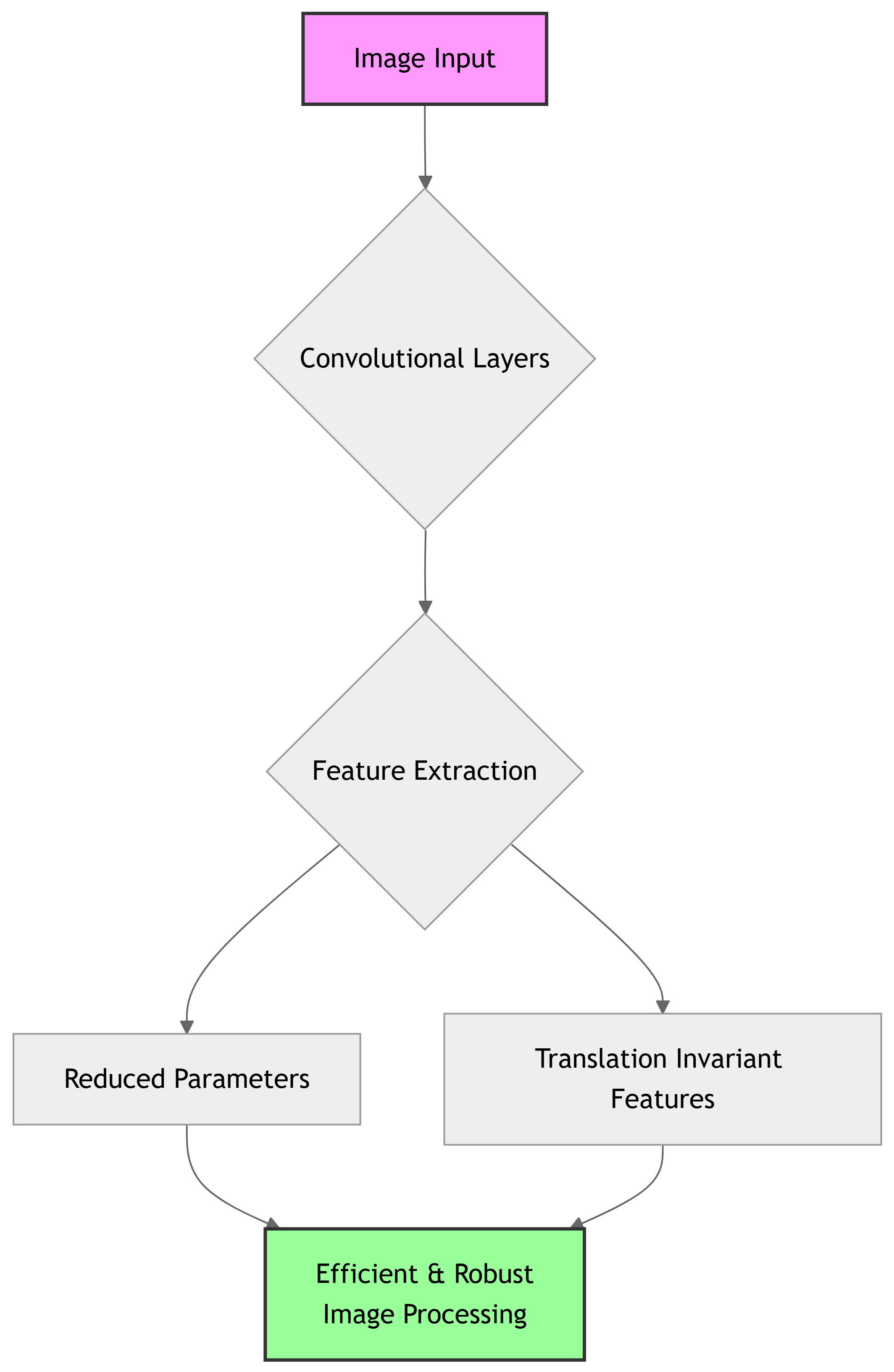
Convolutional Neural Networks (CNNs) to the Rescue!
CNNs are designed to efficiently process image data.
Key Features
- Convolution Operations: Extract features effectively.
- Parameter Sharing: Same weights process different input parts.
- Greatly reduces total trainable parameters.
- Translation Invariance: Detect features regardless of position.
- Kernel slides, detecting patterns like edges or textures.
Important
CNNs leverage local spatial coherence in images.
How CNNs Solve MLP Issues
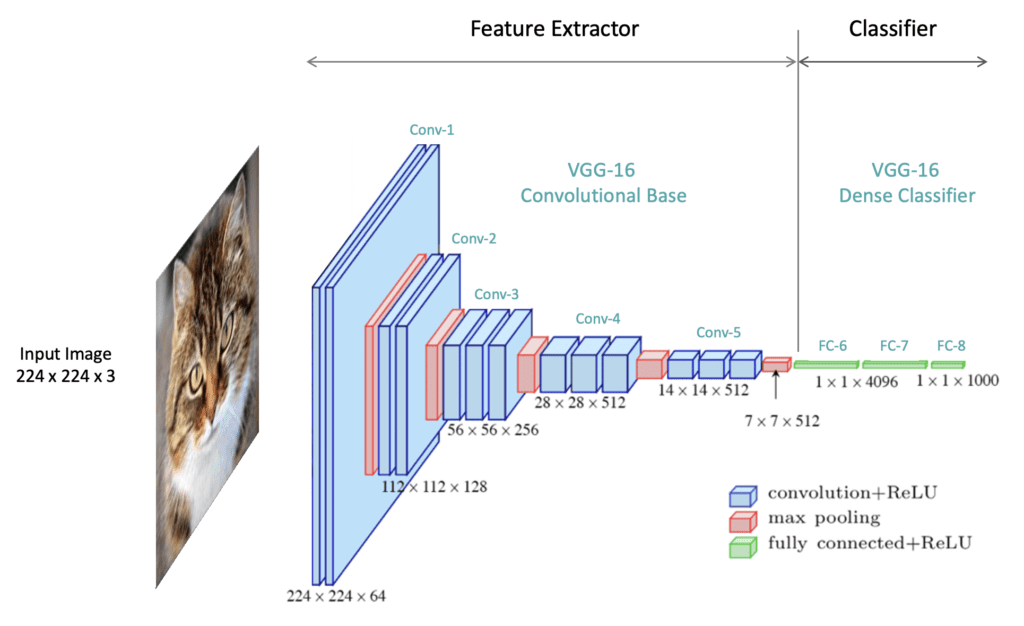
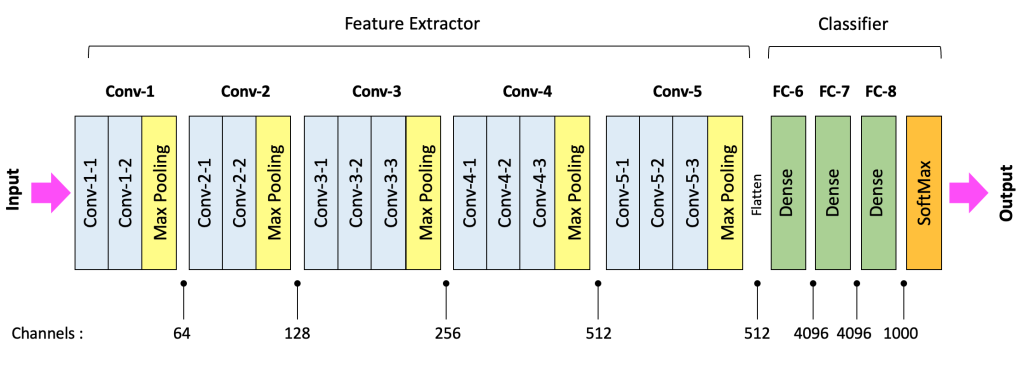
CNN Architecture: Feature Extractor & Classifier
Most CNNs follow a two-part structure:
1. Feature Extractor (Backbone)
- Purpose: Extract meaningful features from raw input.
- Comprises Convolutional Blocks (Conv + Activation + Pooling).
- Spatial dimensions are reduced, depth (channels) increased.
- Example: Input (224x224x3) \(\rightarrow\) Features (7x7x512).
2. Classifier (Head)
- Purpose: Transform extracted features into class predictions.
- Typically uses Fully Connected (Dense) Layers.
- Final layer outputs probabilities (e.g., Softmax).
VGG-16 High-Level Architecture
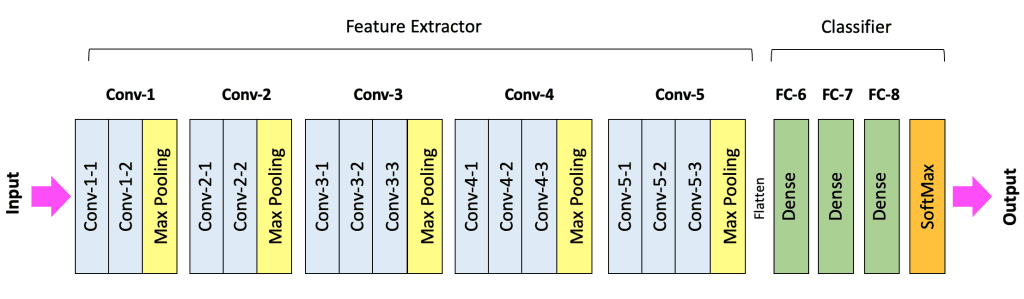
Feature Extractor and Classifier
Convolutional Layers: The “Eyes” of a CNN
Extracting features using learnable filters.
How it Works
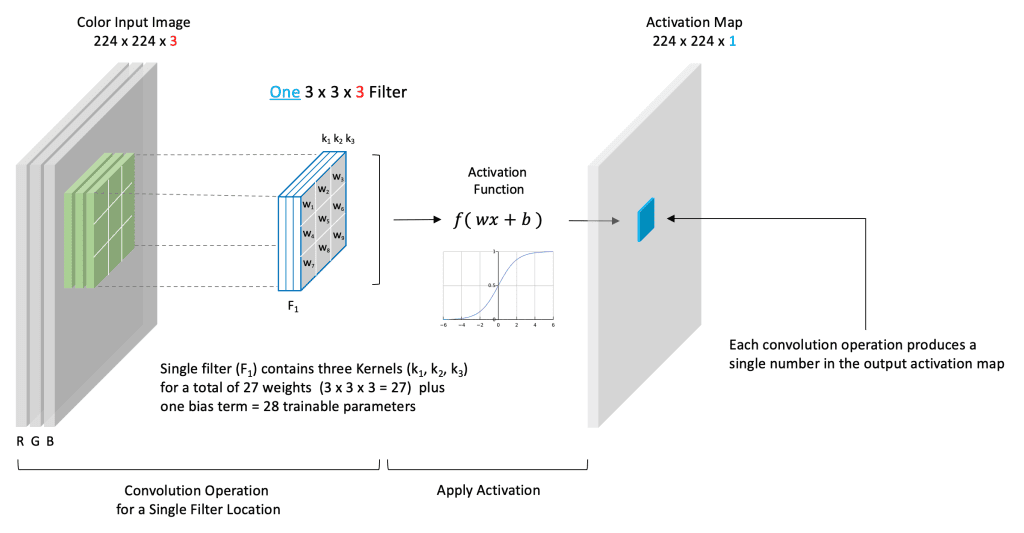
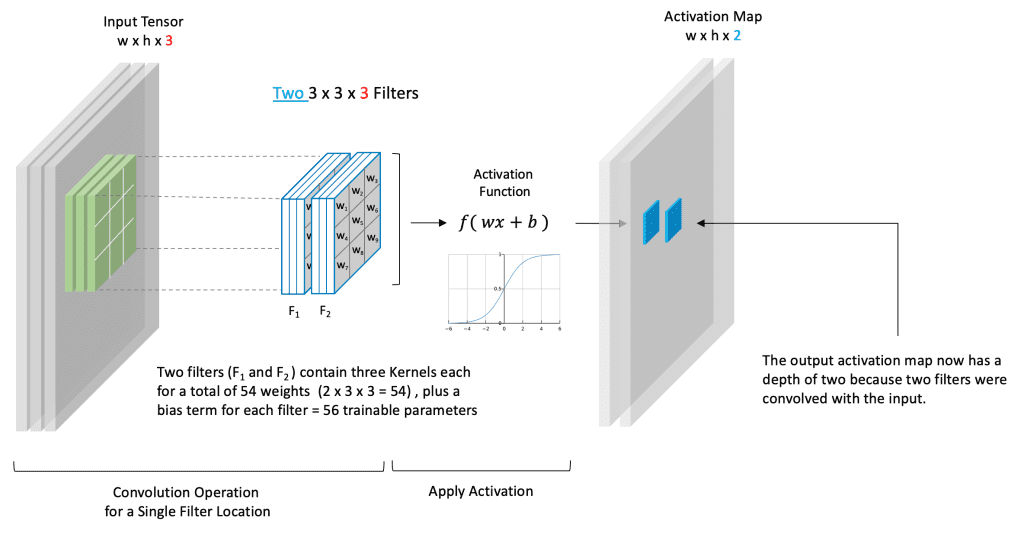
- Input: A 2D array (image or feature map).
- Filter/Kernel: Small
(e.g., 3x3)matrix of weights. - Convolution Operation:
- Filter slides across input data.
- At each position, element-wise multiplication & sum of filter and receptive field.
- Result is a single number.
- Activation Map: Output of the convolution, passed through an activation function.
- Summarizes features from the input.
Conceptual Diagram

Note
Filter weights are learned during training. Unlike fixed filters (e.g., Sobel), CNN filters adapt for optimal feature detection.
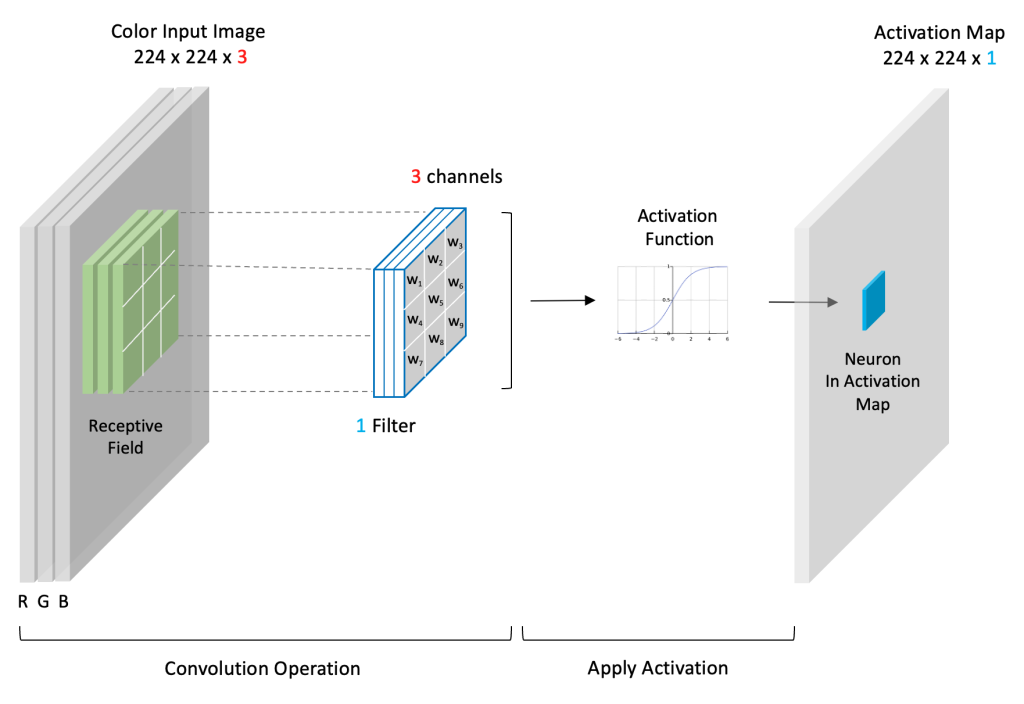
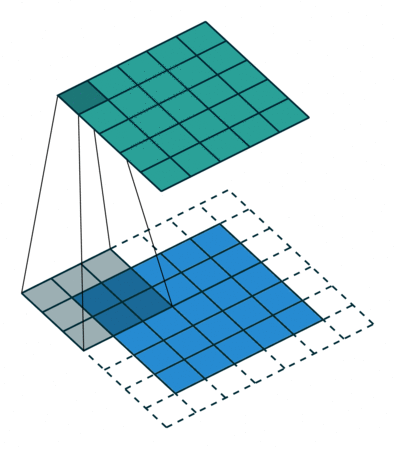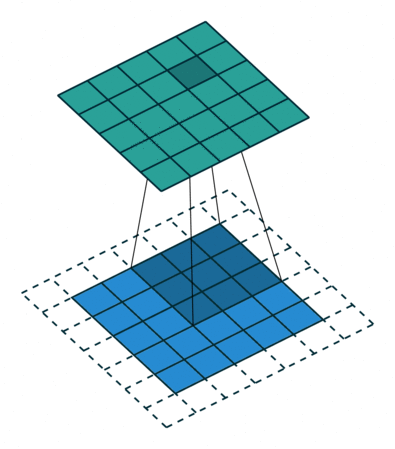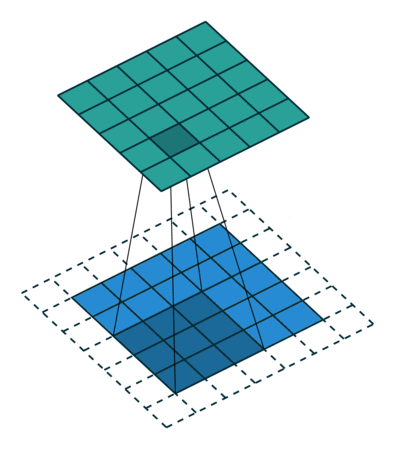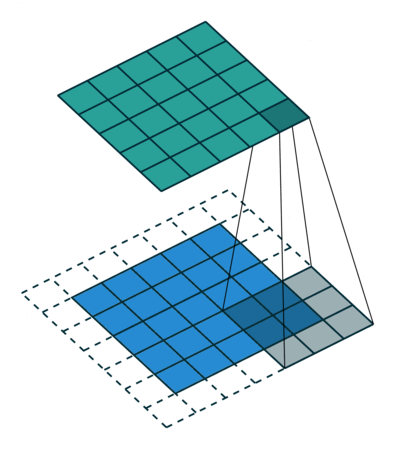
Convolution Operation
Slide
Padding
Padding and Stride
 (https://learnopencv.com/wp-content/uploads/2024/06/padding-stride-2.png)
(https://learnopencv.com/wp-content/uploads/2024/06/padding-stride-2.png)
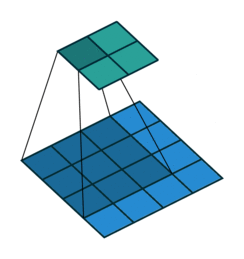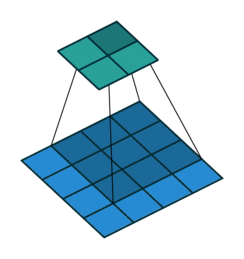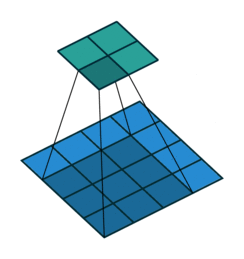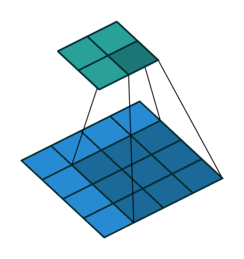 ](https://learnopencv.com/wp-content/uploads/2024/06/no_padding_no_strides.gif)
](https://learnopencv.com/wp-content/uploads/2024/06/no_padding_no_strides.gif)
 ](https://learnopencv.com/wp-content/uploads/2024/06/same_padding_no_strides.gif)
](https://learnopencv.com/wp-content/uploads/2024/06/same_padding_no_strides.gif)
Convolution Output Spatial Size
The output size (O) of a 2D convolution is calculated by:
\[ O = \left\lfloor \frac{n - f + 2p}{s} \right\rfloor + 1 \]
Where: - n: Input size (height or width) - f: Kernel size - p: Padding - s: Stride
Calculate Your Own!
Try different values to see how they affect output size.
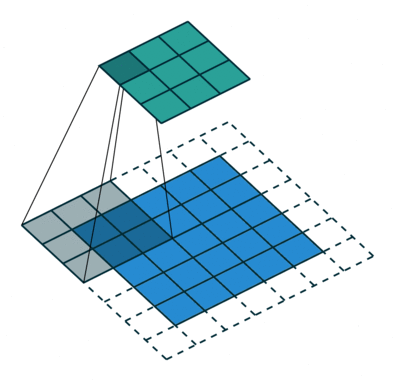
Interactive Convolution Illustration
A basic visual representation of a 2D convolution.

Convolutional Operation
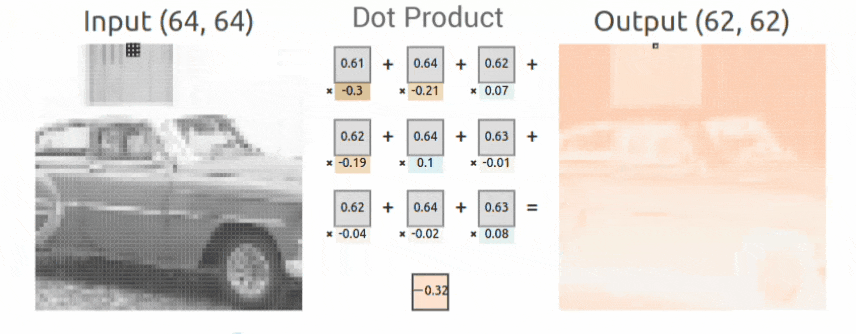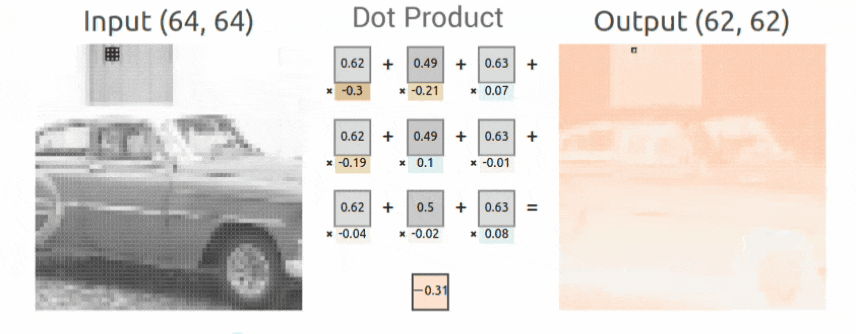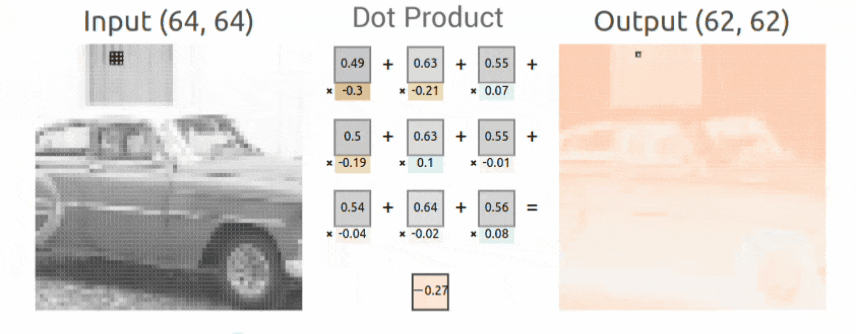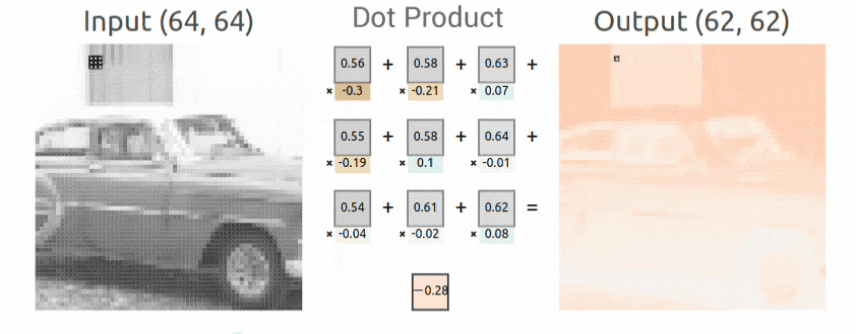
Convolutional Operation
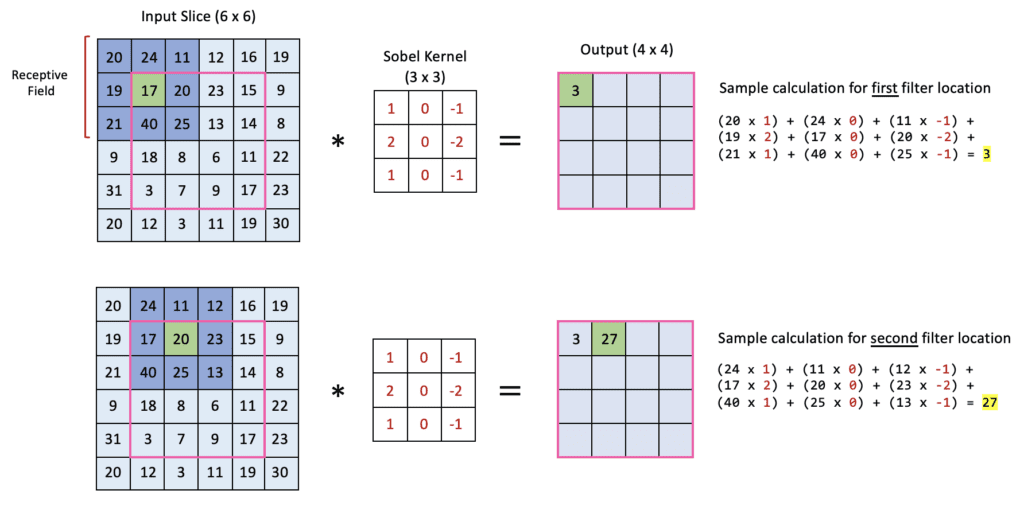
Sobel Kernel: Detecting Vertical Edges
A concrete example of a fixed filter’s operation.
Fixed (Hand-Crafted) Kernel
- Sobel kernel designed to detect vertical edges.
- Comprises positive values on one side, negatives on the other, zeros in middle.
- Acts as a numerical approximation of a derivative in the horizontal direction.
- Output emphasizes sudden intensity changes in the vertical direction.
Note
In CNNs, kernel weights are learned, allowing detection of diverse, complex features, not just predefined edges.
How it Works


Filters
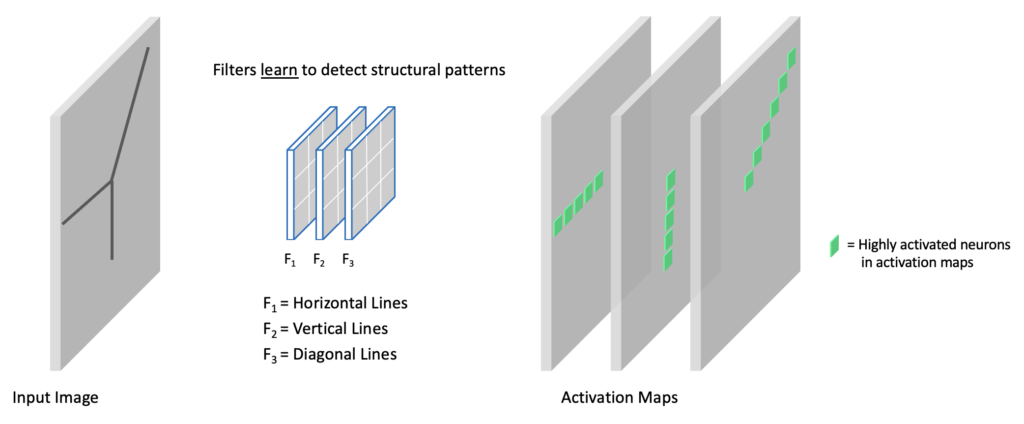
CNNs Learn Hierarchical Features
From simple edges to complex object parts.
Early Layers: Basic Elements
- Filters in the first layers learn simple, fundamental features.
- Examples: Edges (vertical, horizontal, diagonal), color blobs, textures.
- These are general-purpose features.
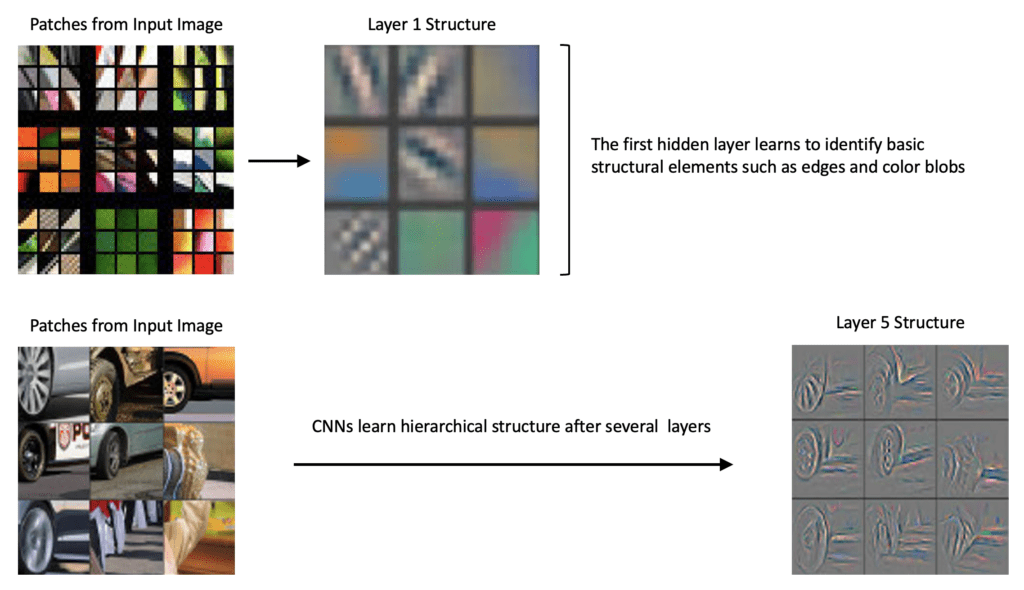
Deeper Layers: Complex Structures
- Filters in deeper layers combine features from previous layers.
- Learn to detect more abstract, composite patterns.
- Examples: Eyes, noses, wheels, ears, specific parts of objects.
Visualizing Feature Learning

Tip
This hierarchical learning is why CNNs are so powerful. They build up complex understanding from simple visual primitives.
Pooling Layers: Spatial Dimension Reduction
Summarizing features and reducing computations.
Purpose
- Downsampling: Reduce spatial size of activation maps.
- Reduced Parameters: Decreases input size to subsequent layers.
- Computation Reduction: Faster inference.
- Overfitting Mitigation: Fewer parameters, less memorization.
- Translation Invariance Boost: Small shifts in input yield less change in pooled output.
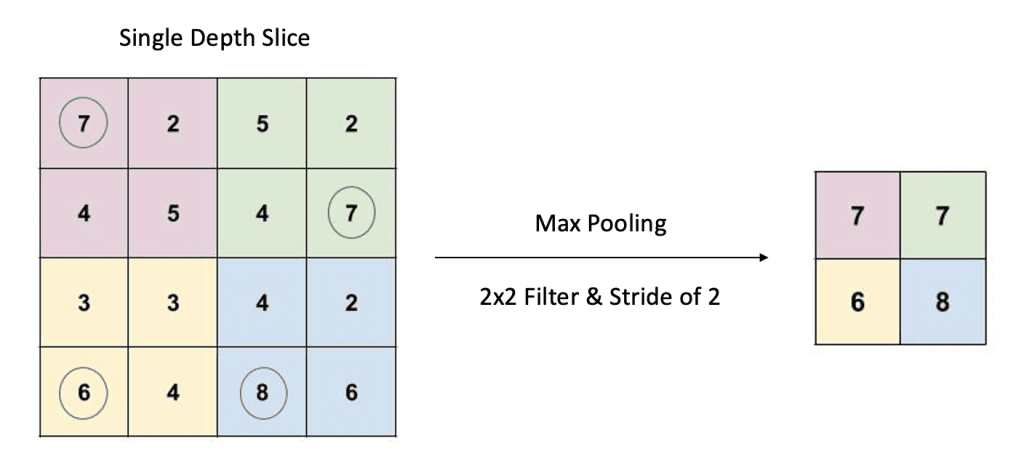
Max Pooling (Most Common)
- A 2D sliding filter (e.g.,
2x2). - Moves across input with a defined stride.
- Outputs the maximum value within the receptive field.
- No trainable parameters in pooling layer itself.
Max Pooling Example
Input 4x4 Activation Map, 2x2 Filter, Stride 2
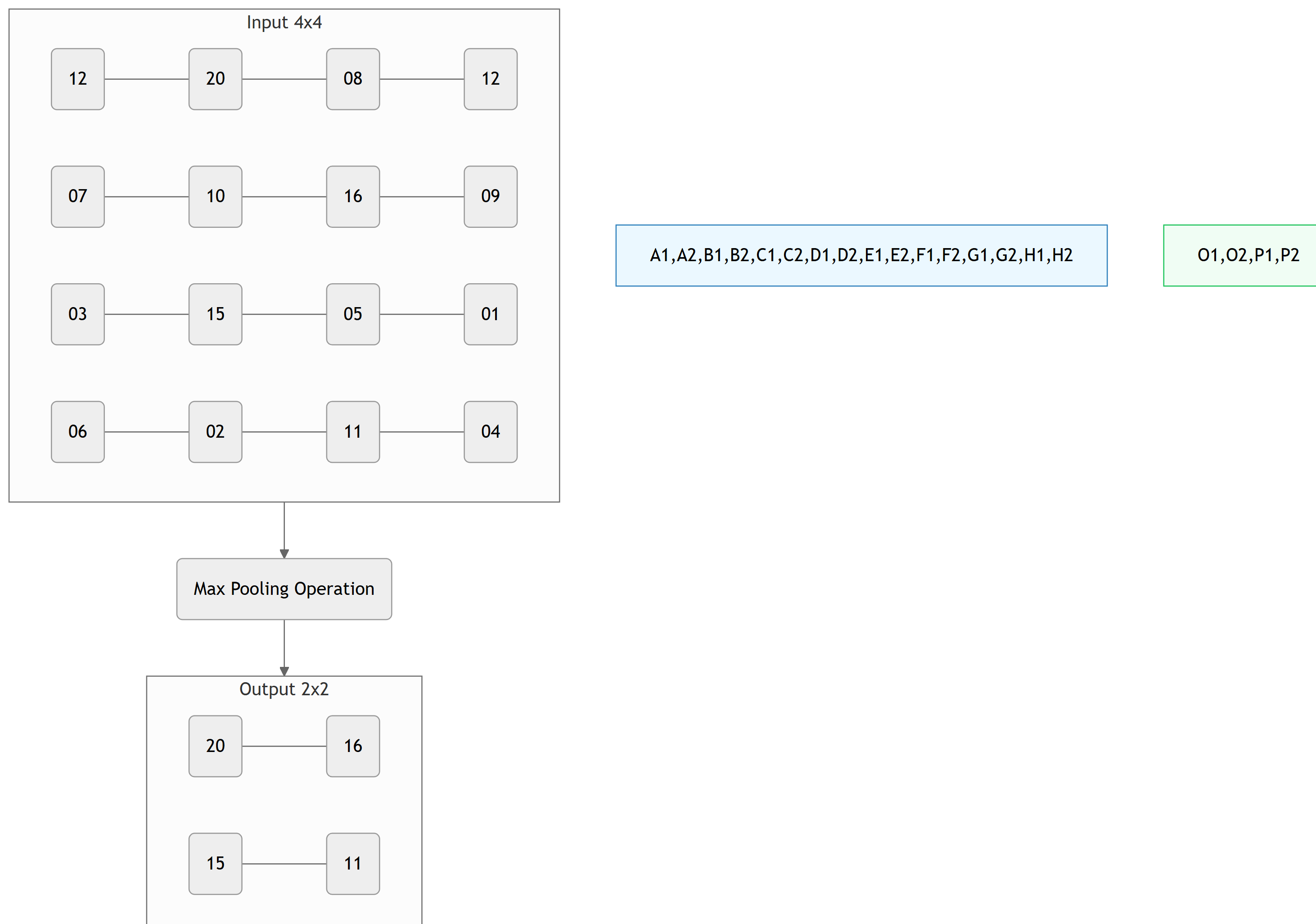
Note
Pooling layers summarily represent features in a smaller space. Think of it as feature aggregation.
The Convolutional Block: Building Blocks of Feature Extraction
Combining convolution and pooling.
Typical Structure
- One or more 2D Convolutional Layers:
- Feature extraction.
- Followed by activation function (e.g., ReLU).
- Followed by a Pooling Layer:
- Spatial dimension reduction.
- Downsize activation maps.
Tip
VGG-16 uses 2-3 convolutional layers before each max pooling layer. Number of filters typically doubles with depth (e.g., 64 \(\rightarrow\) 128 \(\rightarrow\) 256).
Example Block
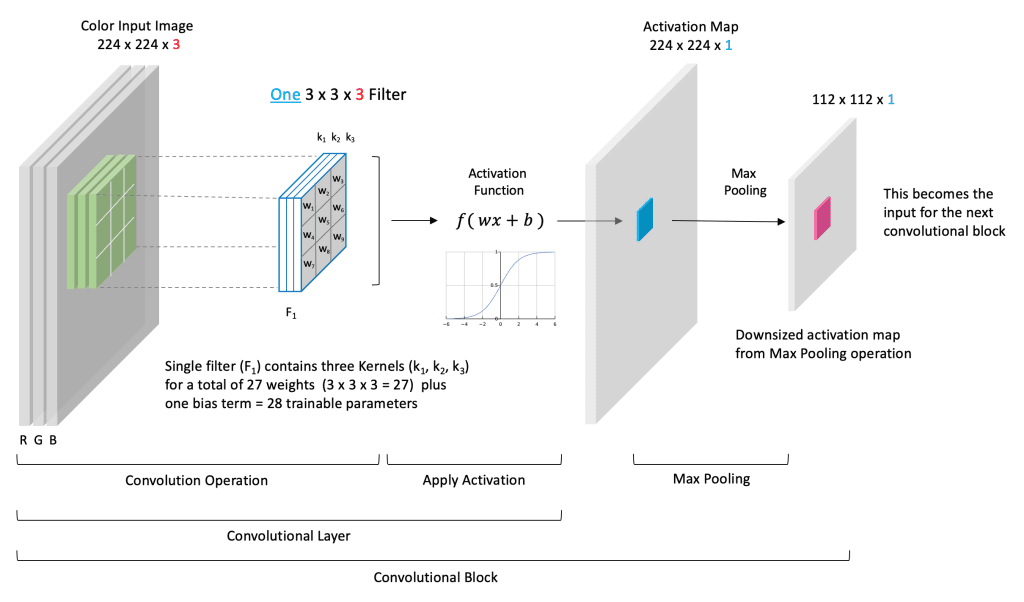
Convolutional Block Detail
Fully Connected Classifier
Mapping extracted features to class probabilities.
Bridging Features to Decisions
- Connects the high-level features from the feature extractor to dense layers.
- Flattening: Output from the last convolutional block (e.g.,
7x7x512) is reshaped into a 1D vector (e.g.,25088features).- Required because dense layers expect 1D input.
- Hidden Dense Layers: Learn complex non-linear combinations of features.
- Output Layer:
- Number of neurons = Number of classes.
- Often uses Softmax activation for multi-class probability output (
[0,1]range, sums to 1).
Classifier Structure

Note
Flattening doesn’t lose spatial information inherently; it just reorganizes it for the dense layer’s input.
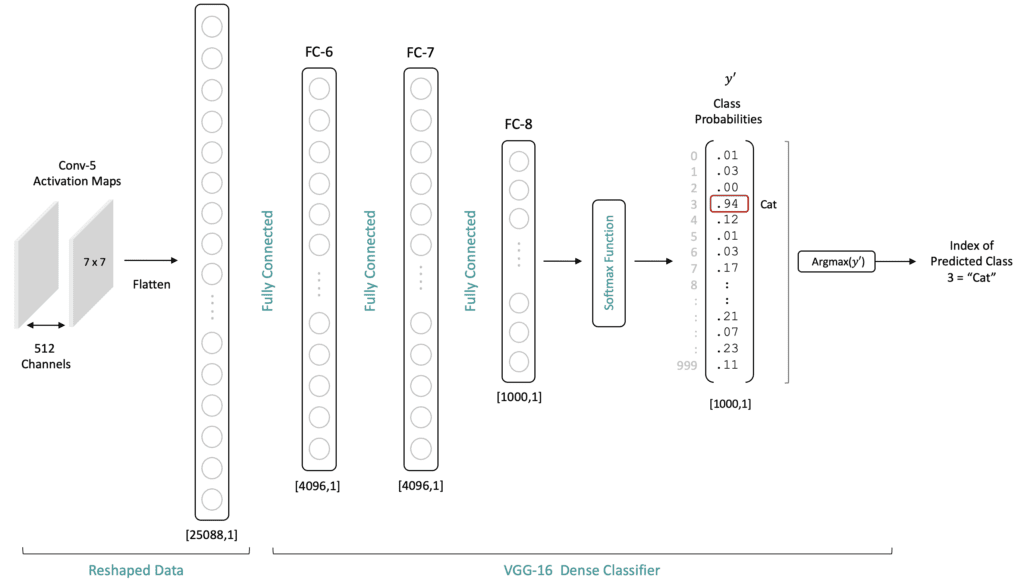
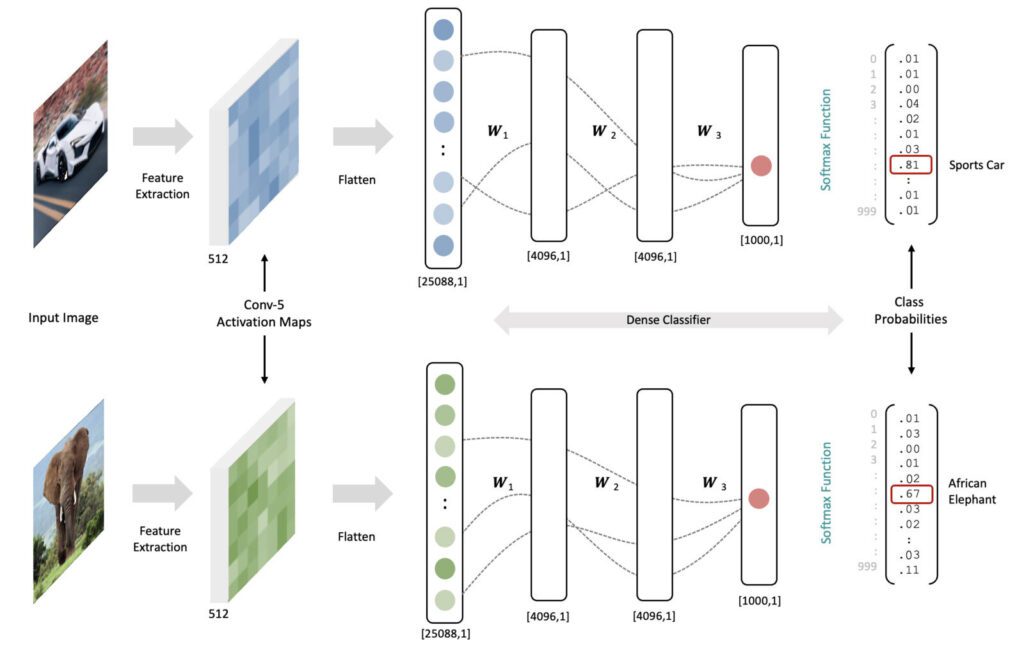
Intuition: How CNNs Map Features to Class Probabilities
Connecting learned features to actionable predictions.
Holistic Understanding of Image Content
- The final activation maps (e.g., 7x7x512) contain rich, meaningful information.
- Each spatial location in these maps retains a relationship to the original input.
- Fully connected layers can process this entire content from the image.
Learned Association
- During training, the weights in the FC layers learn to associate specific feature patterns (from the activation maps) with particular output classes.
- This mapping allows the network to “activate” the correct output neuron based on the combination of features present in the input.
Tip
Minimizing the loss function tunes the weights to effectively map features to class probabilities.
Flow from Features to Prediction

3. 3D Convolution
- Extension of 2D Convolution: Kernel shifts across three axes (height, width, AND depth/time).
- Applications:
- Medical Imaging: Analyzing volumetric data (e.g., MRI, CT scans).
- Video Processing: Capturing spatio-temporal features across frames.
- Benefit: Captures spatial relationships and temporal/depth relationships.
Spatio-temporal Feature Extraction
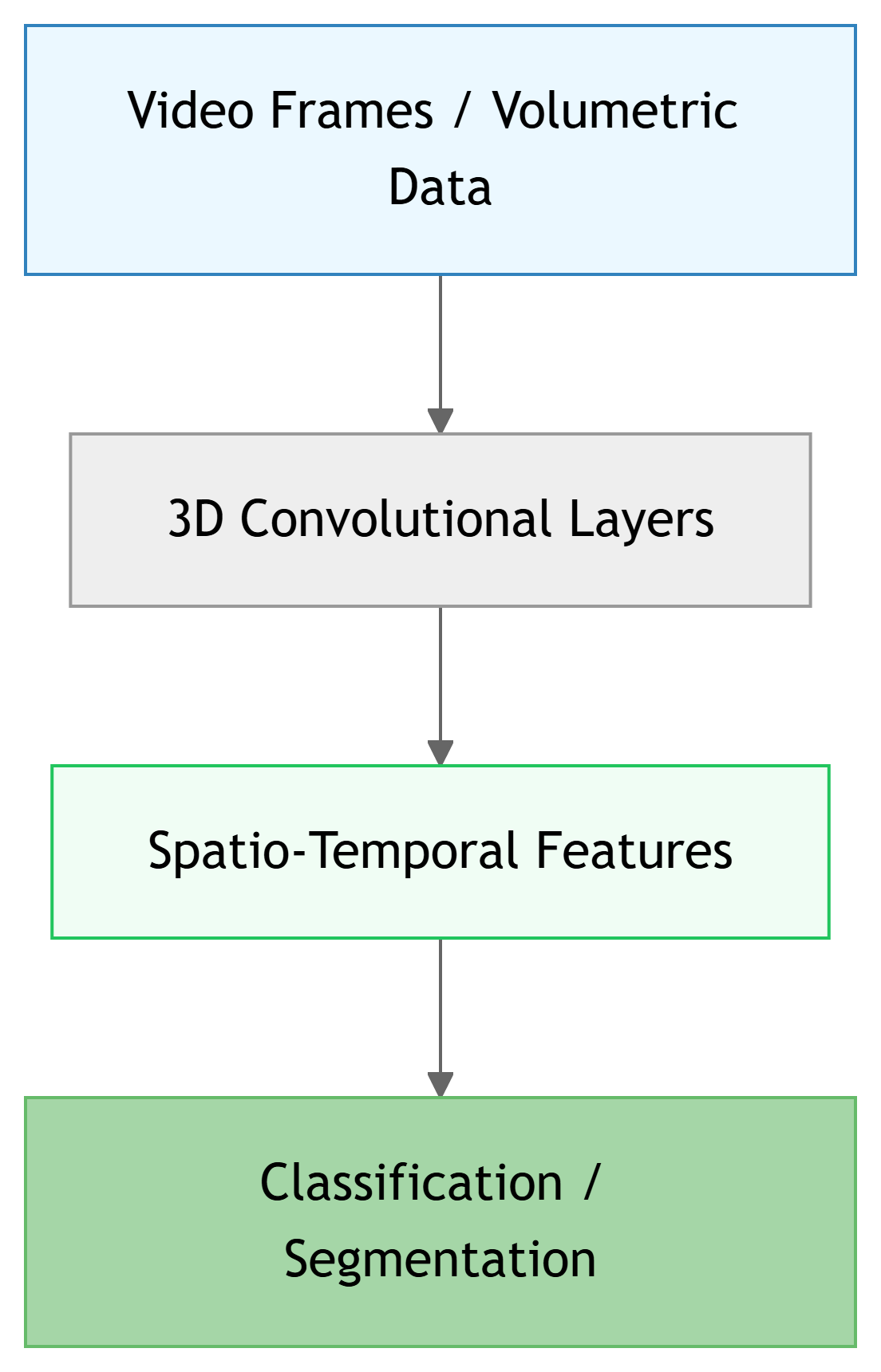
Note
Crucial for dynamic signals and volumetric data in ECE applications.