Having introduced the basic neuron model and neural network architectures, we now delve into practical considerations for setting up a robust machine learning system.
These include:
Data Preprocessing: Preparing input data for optimal network performance.
Weight Initialization: Setting initial values for network parameters.
Batch Normalization: Stabilizing and accelerating training.
Regularization: Techniques to prevent overfitting.
Note
A Neural Network performs a sequence of linear mappings with interwoven non-linearities. These design choices significantly impact training stability and final model performance.
5.1 Data Preprocessing: Centering and Scaling
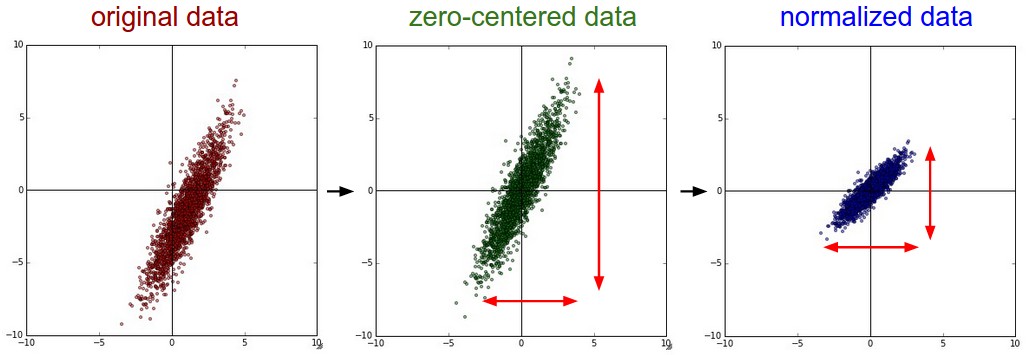
Three common forms of data preprocessing for a data matrix X of size [N x D] (N data, D dimensions).
1. Mean Subtraction
Most common form; centers data around the origin.
X -= np.mean(X, axis = 0) (subtract mean of each feature).
For images, can subtract global mean or per-channel mean.
2. Normalization
Scales data dimensions to approximately same range.
Standardization: Divide by standard deviation after mean-centering: X /= np.std(X, axis = 0).
Min-Max Scaling: Normalize to range [-1, 1].
Useful when features have different scales but similar importance.
Left: Original data. Middle: Zero-centered. Right: Scaled by standard deviation.
Important
Pitfall: Preprocessing statistics must be computed only on training data and then applied to validation/test sets to avoid data leakage.
Interactive Data Preprocessing
Observe the effect of mean subtraction and normalization on a small dataset. Modify the data array and rerun the code.
5.1 Data Preprocessing: PCA and Whitening
Advanced preprocessing techniques for decorrelation and isotropic representation.
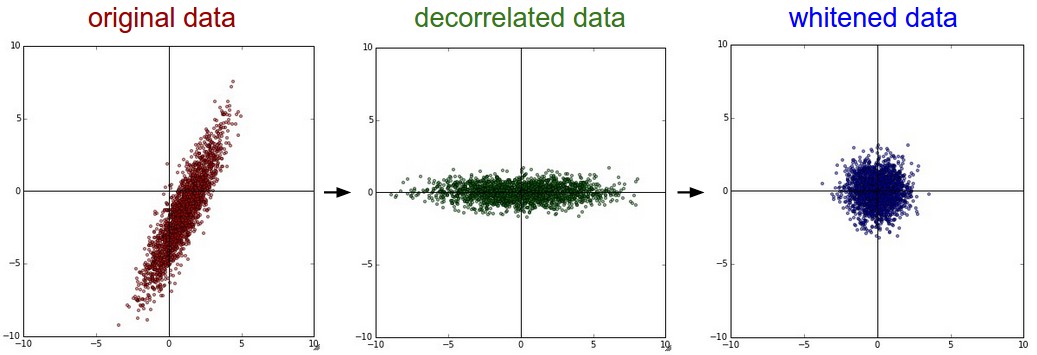
Zero-center the data.
Compute the covariance matrix: cov = np.dot(X.T, X) / X.shape[0].
Reveals feature correlations.
Perform Singular Value Decomposition (SVD) on cov: U,S,V = np.linalg.svd(cov).
U: Eigenvectors (new orthogonal basis).
S: Singular values (related to variance along new axes).
Decorrelate (PCA): Project data onto eigenbasis: Xrot = np.dot(X, U).
Xrot_reduced = np.dot(X, U[:,:k]): PCA dimensionality reduction, keeping k most variant dimensions.
Whitening: Scale decorrelated data by eigenvalues: Xwhite = Xrot / np.sqrt(S + 1e-5).
Transforms data to have zero mean and identity covariance matrix (isotropic Gaussian blob).
Warning
Whitening can exaggerate noise by scaling up low-variance dimensions. A small constant 1e-5 prevents division by zero.
Visualizing PCA/Whitening Transformations
<b>Left</b>: Original toy 2D data.
<b>Middle</b>: After PCA, data is zero-centered and rotated to its eigenbasis (decorrelated).
<b>Right</b>: After Whitening, data dimensions are scaled to unit variance, making it an isotropic Gaussian blob.
Tip
In practice: PCA/Whitening are less common for Convolutional Networks. However, zero-centering is always crucially important, and normalization (dividing by pixel range or standard deviation) is common for images.
PCA Visualization with CIFAR-10 Features
These visualizations demonstrate PCA’s effect on image features, reducing dimensionality while preserving information.
<b>Left:</b> Sample CIFAR-10 images.
<b>2nd Left:</b> Top 144 eigenvectors (basis images); capture lower frequencies.
<b>2nd Right:</b> Images reconstructed from 144 PCA-reduced features (slightly blurrier, but preserved).
<b>Right:</b> Whitened images; higher frequencies exaggerated.
5.2 Weight Initialization
Crucial for network stability and convergence. Poor initialization can lead to vanishing/exploding gradients or slow learning.
Pitfall: All Zero Initialization
W = np.zeros((D, H))
Problem: Every neuron computes the same output, gradients, and updates.
Leads to a symmetric network where all neurons learn the same features.
Result: No symmetry breaking, network effectively becomes a single neuron per layer.
Small Random Numbers (Symmetry Breaking)
W = 0.01 * np.random.randn(D, H)
Initialize weights to small, random values (e.g., from a Gaussian distribution).
Neurons start unique, compute distinct updates, and break symmetry.
Warning
Very small weights can lead to very small gradients during backpropagation, diminishing the “gradient signal” in deep networks.
5.2 Weight Initialization: Calibrating Variances
Problem: Variance of a neuron’s output grows with the number of inputs (n).
Proposed Solution: Scale initial weights by 1/sqrt(n) to normalize output variance.
Heuristic: w = np.random.randn(n) / np.sqrt(n)
Ensures all neurons initially have approximately the same output distribution.
Empirically improves convergence rate.
Derivation Sketch:
For a neuron’s raw activation s = _i^n w_i x_i with zero-mean inputs/weights: \[
\text{Var}(s) = \left( n \text{Var}(w) \right) \text{Var}(x)
\]
To make \(\text{Var}(s) \approx \text{Var}(x)\), we need \(n \text{Var}(w) = 1\), so \(\text{Var}(w) = 1/n\).
If \(w_i \sim N(0, \sigma^2)\), then \(\sigma^2 = 1/n\), so \(\sigma = 1/\sqrt{n}\).
Tip
Current Recommendation (He et al. 2015): For ReLU neurons, use \(\text{Var}(w) = 2/n\). Thus, w = np.random.randn(n) * np.sqrt(2.0/n).
Interactive Weight Initialization Variance
Observe how weight scaling affects the variance of a neuron’s output.
Adjust the number_of_inputs and scaling_factor to see their impact.
Makes networks significantly more robust to bad initialization.
Acts as a form of regularization, reducing reliance on other techniques like Dropout.
Allows for higher learning rates.
5.4 Regularization: Preventing Overfitting
Techniques to control network capacity and improve generalization to unseen data.
L2 Regularization (Weight Decay)
Most common form.
Adds \(\frac{1}{2}\lambda w^2\) to the objective for each weight \(w\).
Intuition: Penalizes large weights, preferring diffuse weight vectors.
Encourages the network to use all inputs a little, rather than some inputs a lot.
During gradient descent, causes weights to decay linearly towards zero: W += -lambda * W.
L1 Regularization
Adds \(\lambda \mid w \mid\) to the objective for each weight w.
Property: Leads to sparse weight vectors (many weights become exactly zero).
Useful for feature selection; neurons rely on a sparse subset of inputs.
Can be combined with L2: Elastic Net Regularization.
Note
L2 regularization generally gives superior performance unless explicit feature selection (sparsity) is desired.
5.4 Regularization: Max Norm & Dropout
Max Norm Constraints
Enforces an absolute upper bound on the magnitude of each neuron’s weight vector.
Weight vector \(\vec{w}\) is clamped to satisfy \(\Vert \vec{w} \Vert_2 < c\) after each update (e.g., \(c=3\) or \(4\)).
Benefit: Prevents “exploding” network activations, even with high learning rates.
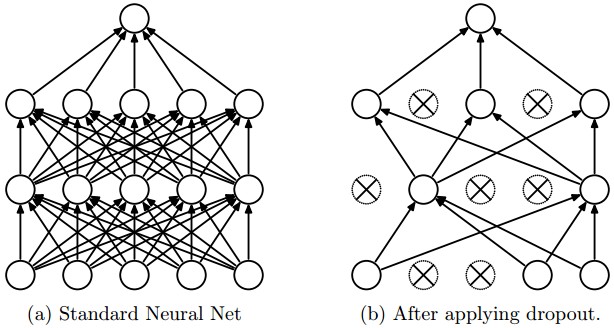
Dropout
Extremely effective and simple regularization technique.
During training, each neuron is kept active with probability \(p\) (hyperparameter, e.g., 0.5) or set to zero otherwise.
Dropout can be seen as training an ensemble of neural networks.
Important
Dropout, L2, L1, and Max Norm address different aspects of overfitting and can often be combined effectively.
Dropout: Implementation
Vanilla Dropout (Not Recommended)
Scales activations at test time.
p =0.5# probability of keeping a unit activedef train_step(X): H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = np.random.rand(*H1.shape) < p # binary mask H1 *= U1 # drop!# ... second layer ...def predict(X): H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale by p# ... second layer ...
Dropout: Implementation
Inverted Dropout (Recommended)
Scales activations at train time, leaving test time untouched.
p =0.5# probability of keeping a unit activedef train_step(X): H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = (np.random.rand(*H1.shape) < p) / p # NOTE: scale by 1/p H1 *= U1 # drop!# ... second layer ...def predict(X): H1 = np.maximum(0, np.dot(W1, X) + b1) # NO scaling needed# ... second layer ...
Tip
In practice: Use a single, global L2 regularization strength (cross-validated) with inverted dropout (p=0.5 is a good default).
Interactive Dropout Simulation
Simulate inverted dropout on a small matrix. Adjust dropout_probability_p to see how many elements are dropped and scaled.
viewof dropout_probability_p = Inputs.range([0.1,1.0], {value:0.5,step:0.1,label:"Dropout Probability (p)"});
6. Loss Functions
The “data loss” component of your objective function. Measures compatibility between prediction (f) and ground truth label (y). Total loss: \(L = \frac{1}{N} \sum_i L_i + \text{Regularization Loss}\).
Also common: squared hinge loss \(\max(0, f_j - f_{y_i} + 1)^2\).
Softmax Loss (Cross-Entropy):\[L_i = -\log\left(\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }\right)\]
Interprets scores \(f_j\) as unnormalized log-probabilities.
Note
Large Number of Classes Problem: For huge label sets (e.g., ImageNet 22k, NLP vocabularies), computing full Softmax is expensive. Solutions like Hierarchical Softmax approximate by structuring labels in a tree.
Interactive Classification Loss Plot
Compare SVM and Softmax loss for a single example prediction. Adjust the correct_class_score and incorrect_class_score to see their impact on loss.
viewof correct_score = Inputs.range([-3,5], {value:2,step:0.1,label:"Score for Correct Class"});viewof incorrect_score = Inputs.range([-3,5], {value:0.5,step:0.1,label:"Score for Incorrect Class"});
6.2 Attribute Classification
Attribute Classification
For multi-label problems where an example can have multiple non-exclusive attributes (e.g., an image with multiple hashtags).
Approach: Build a binary classifier for each attribute independently.
\(y_{ij} \in \{0, 1\}\), \(\sigma(\cdot)\) is the sigmoid function.
6.3 Regression
Regression (Predicting Real-Valued Quantities)
Commonly uses L2 or L1 norm of the difference.
L2 Loss (Squared Error):\[L_i = \Vert f - y_i \Vert_2^2\]
L1 Loss (Absolute Error):\[L_i = \Vert f - y_i \Vert_1 = \sum_j \mid f_j - (y_i)_j \mid\]
Warning
L2 loss is much harder to optimize and less robust to outliers than Softmax. Consider quantizing outputs into bins and performing classification whenever possible for regression tasks.
7. Summary (Part 2)
Data Preprocessing: Crucial for model stability and performance.
Always zero-center data.
Normalize data scale (e.g., by standard deviation).
Compute preprocessing statistics only on training data.
Weight Initialization:
Avoid zero initialization; use small random numbers.
Recommended for ReLU: w = np.random.randn(n) * np.sqrt(2.0/n).
Biases typically initialized to zero.
Batch Normalization:
Stabilizes training and speeds up convergence.
Insert after FC/Conv layers, before non-linearities.
Makes networks robust to poor initialization.
Regularization: Prevents overfitting.
Commonly use L2 regularization and inverted Dropout (p=0.5 is a good default).