graph LR
Input["Input Image (x)"] --> W1_Layer("Layer 1 - W1")
W1_Layer --> Nonlinearity["Non-Linear Activation (max(0, .))"]
Nonlinearity --> W2_Layer("Layer 2 - W2")
W2_Layer --> Scores["Output Scores (s)"]
style Input fill:#f9f,stroke:#333,stroke-width:2px;
style Scores fill:#bbf,stroke:#333,stroke-width:2px;
Machine Learning
1.5 Neural Networks Part 1: Setting up the Architecture
2. Modeling One Neuron: Biological Motivation
Biological Neuron (Left):
- Dendrites: Receive input signals.
- Cell Body: Integrates signals.
- Axon: Transmits output signals.
- Synapses: Connections to other neurons, with variable strengths.
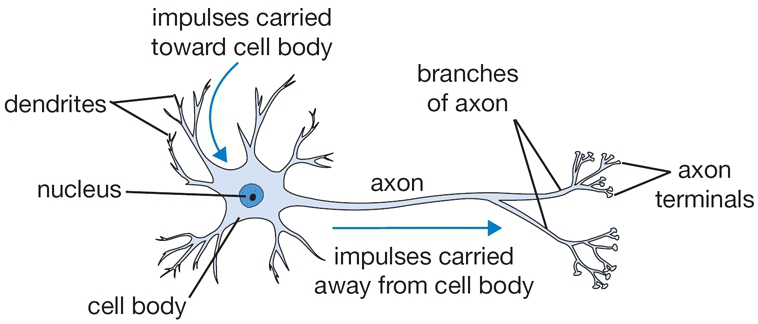
A cartoon drawing of a biological neuron.
Computational Model (Right):
- Inputs (\(x_i\)) correspond to signals from other neurons.
- Weights (\(w_i\)) represent synaptic strengths (learnable).
- Summation: \(_i w_i x_i + b\) (cell body processing).
- Activation function (\(f\)): Simulates firing rate.

Mathematical model of a neuron.
3. Commonly Used Activation Functions
An activation function (or non-linearity) takes a single number and performs a fixed mathematical operation.
Sigmoid Function \((x) = 1 / (1 + e^{-x})\)
- Squashes real numbers to range [0, 1].
- Historically popular for “firing rate” interpretation.
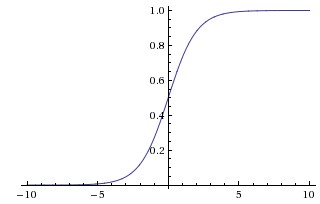
Sigmoid non-linearity.
Warning
Drawbacks:
- Saturates and kills gradients: At tails (0 or 1), gradient is near zero, hindering learning.
- Non-zero-centered output: Can lead to zig-zagging gradient updates.
Tanh Function \((x) = 2 (2x) -1\) * Squashes real numbers to range [-1, 1]. * Zero-centered output - an improvement over sigmoid.
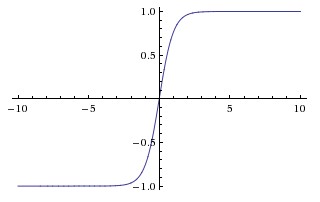
Tanh non-linearity.
Note
Preferred over Sigmoid: Due to its zero-centered output, it generally performs better than sigmoid. Still suffers from saturation.
Activation Functions: ReLU and Variants
Rectified Linear Unit (ReLU) \(f(x) = (0, x)\)
- Output is 0 for negative input, \(x\) for positive input.
- Pros:
- Accelerates convergence significantly.
- Computationally efficient (simple thresholding).
- Does not saturate in the positive region.
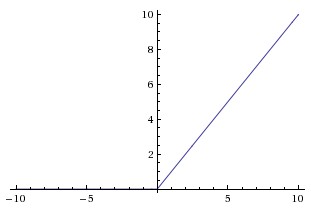
ReLU activation function.
ReLU Cons & Variants:
- “Dying ReLU” problem: Neurons can become inactive (output 0) for all future inputs if gradients are too large.
- Leaky ReLU: \(f(x) = (x < 0) (x) + (x ) (x)\)
- Introduces a small positive slope \(\) for negative inputs (e.g., 0.01).
- Aims to prevent dying ReLUs.
- Maxout: \((w_1^Tx+b_1, w_2^Tx + b_2)\)
- Generalizes ReLU and its leaky version.
- No saturation, no dying problem.
- Drawback: Doubles the number of parameters per neuron.
Warning
For ReLU, monitor “dead” units. High learning rates can exacerbate the dying ReLU problem.
4. Neural Network Architectures
Layer-wise Organization
Neural Networks are collections of neurons connected in an acyclic graph. Most common organizations are into distinct layers.
Fully-Connected Layer:
- Neurons between adjacent layers are fully pairwise connected.
- Neurons within a single layer share no connections.
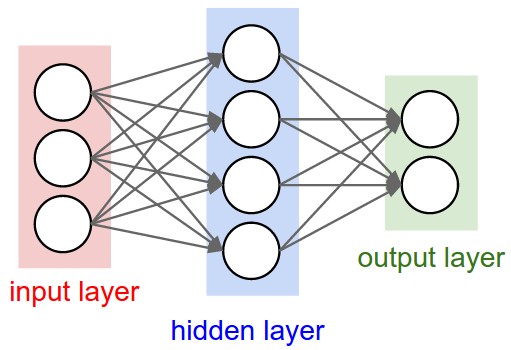
Two-layer Neural Network topology.
Example - 3-Layer Network:
- Three inputs.
- Two hidden layers, each with 4 neurons.
- One output layer.

Three-layer Neural Network topology.
Setting Number of Layers and Their Sizes
Network Capacity: The ability of a model to approximate complex functions. Increases with more layers and neurons.
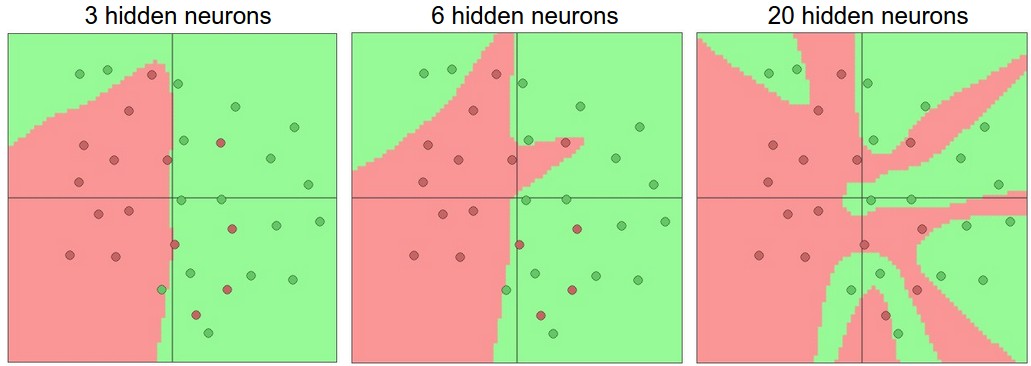
Larger NNs can represent more complicated functions. Circles are data points, colors are classes, decision regions by trained NNs. (ConvNetsJS demo)
- Overfitting: When a high-capacity model learns noise in training data instead of underlying patterns.
- Left: 1 hidden neuron - too low capacity, underfits.
- Middle: 3 hidden neurons - good balance.
- Right: 20 hidden neurons - very high capacity, potentially overfits by creating complex, disjoint decision regions.
Controlling Overfitting: Prioritizing Regularization
Counterintuitive Advice:
- Don’t use smaller networks to prevent overfitting.
- Smaller networks are harder to train effectively with gradient descent; they often converge to “bad” local minima.
- Larger networks have many more local minima, but these tend to be better in terms of actual loss.
Note
Always use as big of a neural network as your computational budget allows!
Preferred Strategy:
- Use a large network to ensure high capacity.
- Control overfitting with robust regularization techniques.
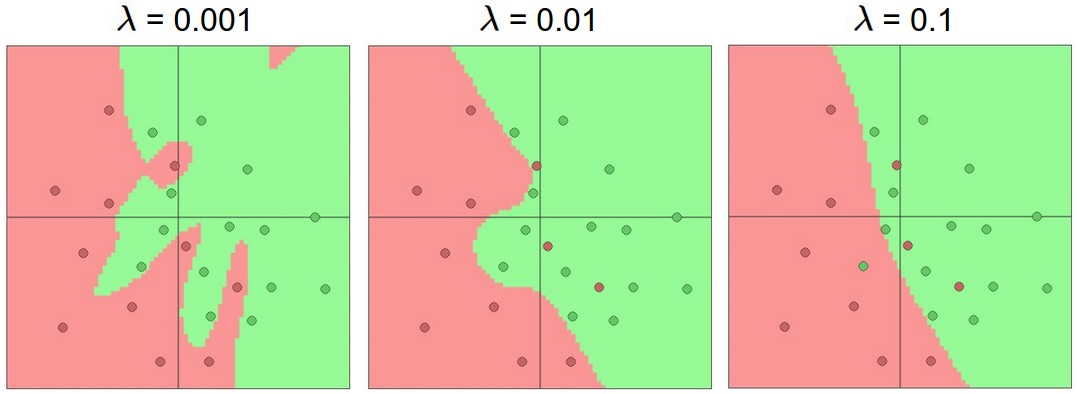
Effects of regularization strength (20 hidden neurons each). Stronger regularization yields smoother decision regions. (ConvNetsJS demo)