Machine Learning
Image Classification: Data-driven Approach, k-Nearest Neighbor, train/val/test splits
What is Image Classification?
Given: A set of images, each labeled with a single category (e.g., “cat”, “dog”, “car”).
Goal: Train a model to predict the category of new, unseen images.
ECE Relevance:
- Autonomous Systems: Object detection in self-driving cars.
- Medical Imaging: Diagnosing diseases from X-rays or MRI scans.
- Quality Control: Detecting defects in manufacturing.
- Signal Processing: Classifying radar or sonar signals into object types.

Data Splitting: The Holy Trinity
To correctly tune hyperparameters, we divide our data into three distinct sets:
- Training Set (e.g., 60-80%):
- Used to train the model (e.g., storage for k-NN).
- The model learns from this data.
- Validation Set (e.g., 10-20%):
- A “fake test set” used to tune hyperparameters.
- Provides an unbiased estimate of model performance during development.
- Test Set (e.g., 10-20%):
- Used for a single, final evaluation of the chosen model.
- Provides an unbiased estimate of generalization performance on truly unseen data.

Important
Golden Rule: The Test Set is used only once, at the very end!
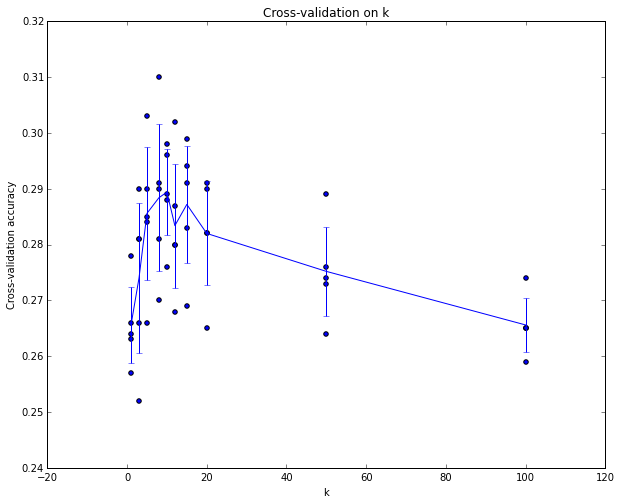
When Validation Data is Small: Cross-Validation
- Problem: If your dataset is small, a single validation split might not be representative (noisy estimate).
- Solution: Cross-validation provides a more robust estimate of performance for hyperparameter tuning.
How it works (e.g., 5-fold CV):
- Divide the training data into
Nequal “folds” (e.g., 5). - Iterate
Ntimes:- Use
N-1folds for training. - Use the remaining 1 fold for validation.
- Record performance for the current hyperparameter setting.
- Use
- Average the performance across all
Niterations.
Tip
Common folds: 3, 5, or 10. More folds offer a better estimate but are more computationally expensive.
The Curse of Dimensionality & Image Data
Why pixel-based distances fail for images
Pixel-based L1 or L2 distances often correlate more with background and general color distribution than with semantic content.

Warning
The image on the left is the original. The three images next to it are all equally far away by L2 pixel distance. Notice: The L2 distance suggests they are equally similar, despite huge perceptual differences.
- A truck and a horse can be “closer” if they share a similar background or lighting.
- Semantic meaning (“what the image is”) is lost in raw pixel comparisons.
Visualizing Failure: t-SNE Embedding of CIFAR-10
t-SNE (t-Distributed Stochastic Neighbor Embedding) helps visualize high-dimensional data in 2D or 3D, preserving local neighborhood structures.
Important
Observation: Images nearby in this embedding (meaning they are pixel-wise similar) are clustered by background/color, not by their semantic class (e.g., “dog”, “cat”, “car”).