Machine Learning
5. Deep Learning: AE, TL
Encoder
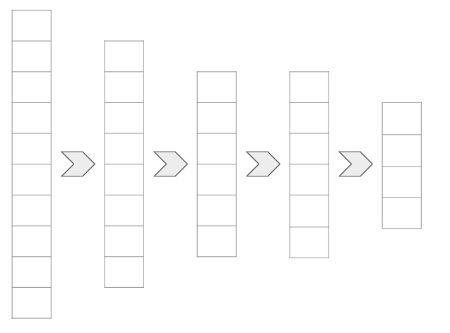
The encoder is a neural network that transforms input data into a smaller,
lower-dimensional representation.
- Goal: Reduce data dimensionality while retaining essential information.
- Layers: Can use dense, convolutional, pooling layers, etc.
- Output: A compressed “latent space” representation.
Decoder
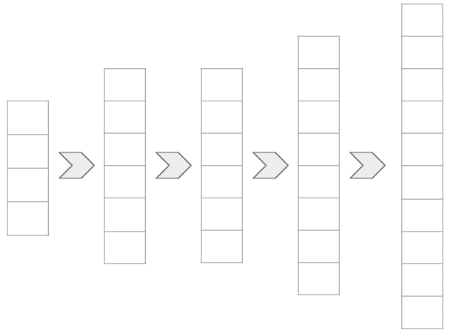
The decoder performs the reverse operation of the encoder.
- Input: The compressed latent representation from the encoder.
- Goal: Reconstruct an approximation of the original input data.
- Method: Expands the data back to its original dimensions.
Autoencoder
Combining the encoder and decoder forms an autoencoder.
- Encoder: Learns efficient data representation.
- Decoder: Reconstructs data from the encoded representation.
- “Lossy” Compression: Output is an approximation, not exact replica.
Important
The autoencoder aims to reconstruct its own input.
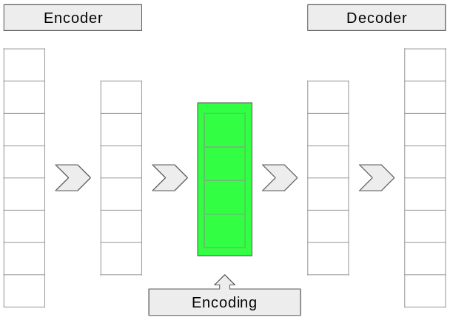
Image Classification Project: Chest X-rays
You will work with a dataset of chest X-ray images.
- Task: Classify images as either
NORMALorPNEUMONIA.
- Source: Dataset from Kaggle, pre-divided for training, testing, and validation.
- Relevance: Demonstrates ML application in medical diagnostics.
Transferring Knowledge: Human Analogy
Just as humans learn by building upon existing knowledge,
ML models can benefit from “transferred” insights.
- Direct Learning: Observing examples directly.
- Knowledge Transfer: Gaining insights from others’ experiences or related domains.
- Efficiency: Speeds up the learning process for new, related tasks.

Transferring Knowledge: The Zebra Example
Imagine identifying a zebra:
- Knowns: Horse shape, tiger stripes, penguin colors.
- Transferred Knowledge: Combining these known features accelerates zebra identification.
- ML Parallel: A model good at general image recognition can quickly adapt to new categories.

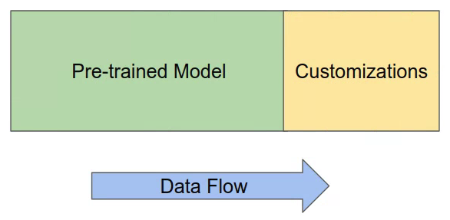
Transfer Learning: High-Level Overview
Typically involves attaching new layers to a pre-trained base model.
- Pre-trained Model: Base model with learned weights (e.g., ImageNet classifier).
- Customization Model: New, untrained layers added on top.
- Data Flow: Input goes through pre-trained model, then into new layers.
- Output: The final prediction from the new layers.
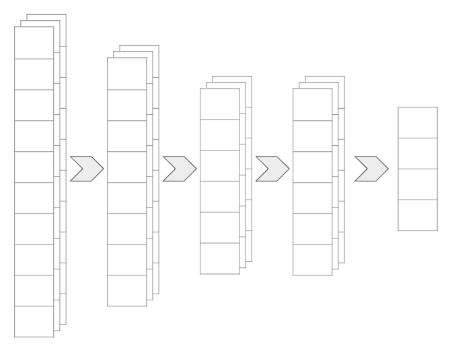
Which Output Layer to Use?
When using a pre-trained model, we typically don’t use its final classification layer.
- Problem: Final layers usually flatten data into class-specific vectors.
- Solution: Use an intermediate high-dimensional layer as the output from the pre-trained model.
- Benefit: Provides rich feature representations for the new custom layers.
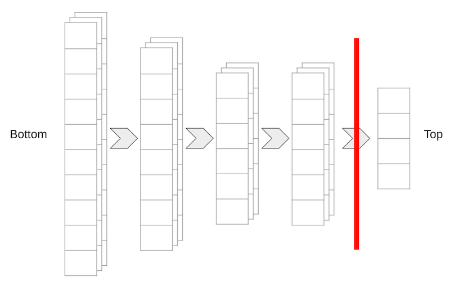
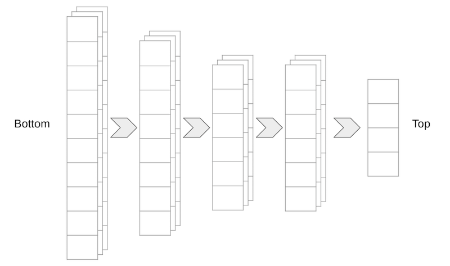
Model Terminology: “Bottom” and “Top”
Understanding these terms helps when configuring pre-trained models.
- “Bottom”: Refers to the input layers of the model.
- “Top”: Refers to the output layers of the model.
This convention often comes from how models are diagrammed, with input at the bottom and output at the top.
include_top: A Key Parameter
Many pre-trained models (e.g., in Keras) offer an include_top parameter.
include_top=True(default): Includes the original classification layers.
include_top=False: Excludes the original classification layers.- Benefit: Provides a high-dimensional feature extractor.
- Use Case: Ideal for building custom classifiers on top.
- Benefit: Provides a high-dimensional feature extractor.