graph TD
A["Raw Text"] --> B{"Feature Extraction / Embeddings"};
B --> C["Machine Learning Model"];
C --> D["Supervised Task (e.g., Classification, Generation)"];
Machine Learning
5. Deep Learning: CNN, RNN, NLP
The Biological Inspiration: Visual Cortex
In the 1960s, research by David Hubel and Torsten Wiesel revealed how the visual cortex processes visual information.
- Neurons respond to specific regions of the visual field.
- Each neuron has a “receptive field.”
- Spatially close neurons have similar, overlapping receptive fields.

Receptive Fields and Image Formation
Our visual system integrates information from these small receptive fields.
This process forms the complete images we perceive.
This biological mechanism provided a key inspiration for Convolutional Neural Networks (CNNs).

Introduction to Convolutional Neural Networks (CNNs)
Inspired by the visual cortex, CNNs emerged in the 1980s.
CNNs are specialized neural networks for processing structured grid data, like images.
They incorporate unique layer types:
- Convolutional Layers
- Downsampling Layers
- Pooling Layers

CNN Architecture Flexibility
The power of CNNs lies in their flexible architecture.
Different combinations and ordering of layers lead to varied results.
This allows for optimization based on the specific task.

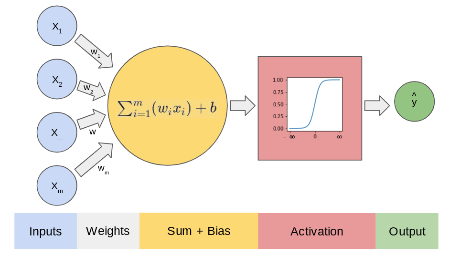
Recall: The Perceptron
The simplest building block of a typical neural network.
A basic computational unit that processes inputs to produce an output.
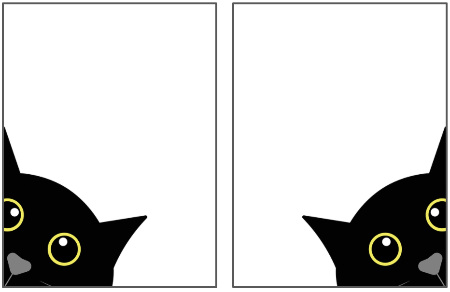
Issues with Multi-Layer Perceptrons (Plain ANNs) for Images
Sensitivity to Input Changes:
- Small shifts in image data can drastically alter learned parameters.
- E.g., a cat’s position in an image should not change its recognition.
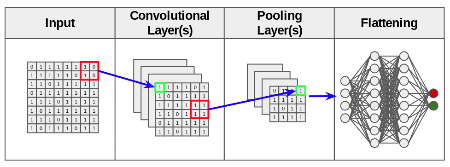
CNNs: A Solution for Image Data
CNNs introduce specialized layers to address the limitations of plain ANNs for image processing.
The processed output then feeds into a fully connected neural network.
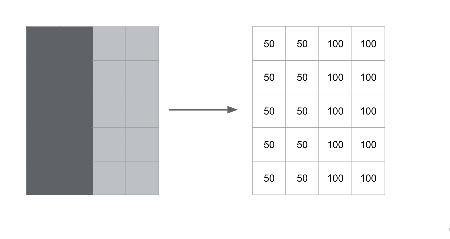
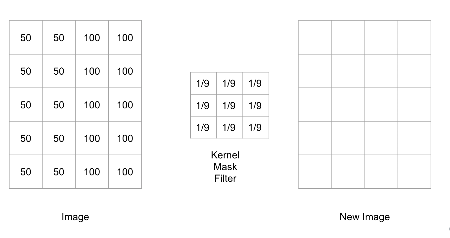
Convolution Example: Input Image
Consider a simple image: a rectangle with two shaded halves.
Pixel intensities are represented numerically.
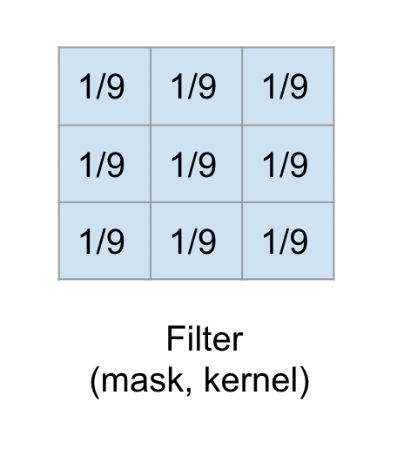
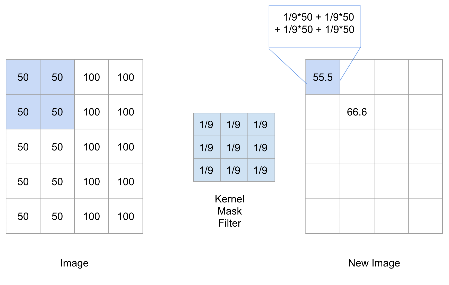
Convolution Example: Blurring Filter
We apply a 3x3 filter designed to create a blurring effect.
Each element in the filter has a specific weight.
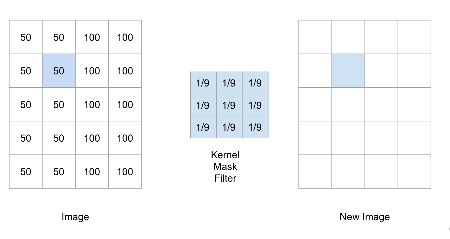
Convolution Example: Filter Application
The filter is applied by sliding it over the image.
At each position, it computes a new pixel value.
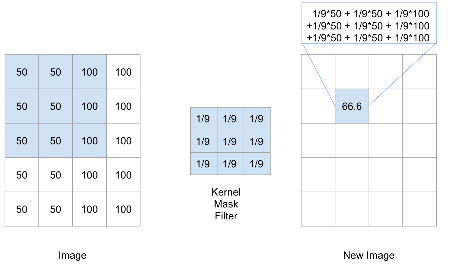
Convolution Example: Calculating a New Pixel Value
To calculate the new value for a pixel:
- Center the filter on the target pixel.
- Multiply corresponding values from the filter and the image.
- Sum the products.
Convolution Example: Result of Blurring
The new pixel value is an average of its neighbors.
This averaging effect reduces sharp intensity changes, leading to blurring.
Handling Edges: Padding
When the filter reaches the image edge, padding is often used.
Commonly, the original image is padded with zeros around its borders.
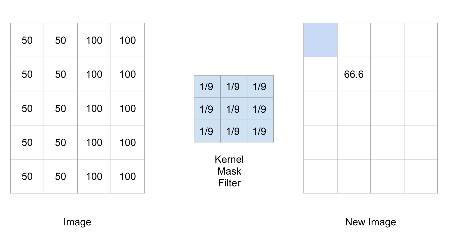
Edge Handling: Relevant Filter Area
The padding ensures the filter can be centered on edge pixels.
Only the part of the filter overlapping the original image contributes to the sum.
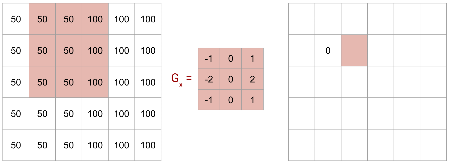
Line Detectors: Gx and Gy Kernels
These kernels are designed to detect sharp intensity changes, indicating lines or edges.
- \(G_x\): Detects vertical lines.
- \(G_y\): Detects horizontal lines.

Line Detector Example: Input Image
An image with a vertical line where shading changes.
We will apply the \(G_x\) kernel to detect this line.
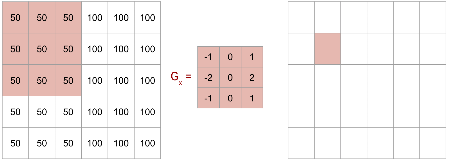
Line Detector Example: First Pixel
Applying \(G_x\) to the first 3x3 block yields 0.
No intensity change within this block.
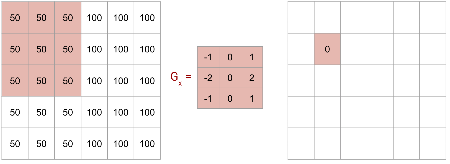
Line Detector Example: Shifting Right
Shifting the \(G_x\) kernel one pixel to the right.
The kernel now straddles the intensity change.
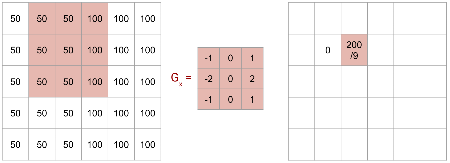
Line Detector Example: Detecting the Edge
The calculation results in a non-zero value (\(200/9\)).
This indicates the presence of a vertical edge.
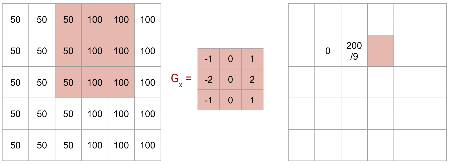
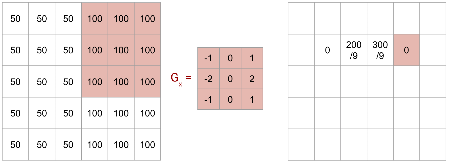
Line Detector Example: Further Shift
Shifting the \(G_x\) kernel one more pixel to the right.
The kernel is now fully on the right side of the edge.
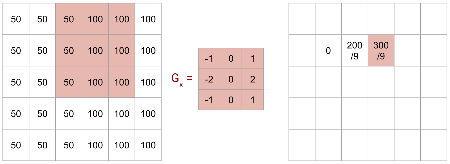
Line Detector Example: Another Non-Zero
The calculation results in \(300/9\).
This continues to highlight the edge region.
Line Detector Example: Past the Edge
Shifting the \(G_x\) kernel one final pixel to the right.
The kernel is now past the intensity change.
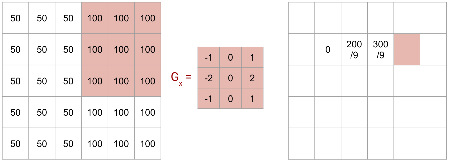
Line Detector Example: Back to Zero
The calculation returns 0 again.
This demonstrates that \(G_x\) effectively detects vertical lines by identifying sharp horizontal intensity transitions.
CNNs Learn Features
In CNNs, the kernel values are learned during training.
The network automatically identifies important features.
We don’t explicitly tell the model what to look for (e.g., “vertical lines”).
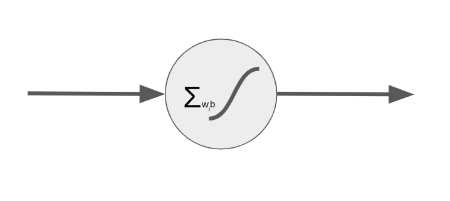
The Feedforward Neuron
- Receives inputs from the previous layer.
- Multiplies inputs by weights, adds bias.
- Passes sum through an activation function.
- Output goes to the next layer.
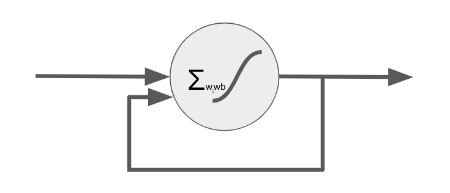
The Recurrent Neuron
A feedforward neuron with a crucial addition:
- Its output feeds back into its own inputs.
- This creates a “memory” over time.
- Allows processing of sequential data.
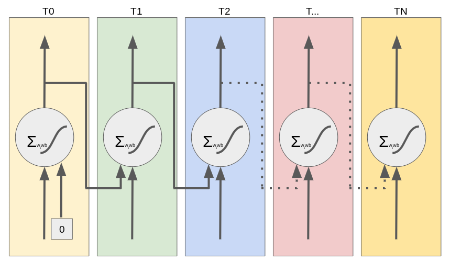
Unrolling a Recurrent Neuron Over Time
Visualizing the data flow:
- Starts with a seeded input (often zero).
- At each time step, it processes current input and its own previous output.
- Passes data to the next layer and forward in time to itself.
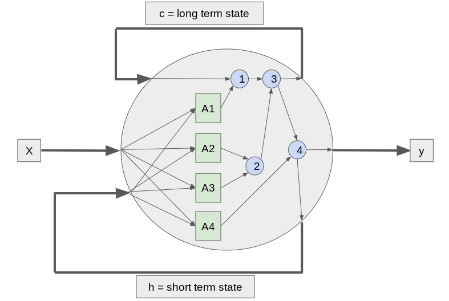
The Long Short-Term Memory (LSTM) Neuron
Addresses the “short memory” problem of standard RNNs.
- Passes two weights back to itself:
- Long-term memory
- Short-term memory
- Long-term memory
- Uses “gates” (forget, input, output) to control information flow.
Time Series Data
Time series data is an ordered set of data points indexed by time.
The inherent ordering makes it ideal for RNNs.
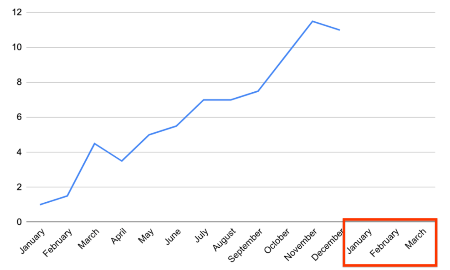
What Are We Predicting?
Sequence prediction aims to forecast future values based on historical data.
Example: Predicting the next quarter’s performance from a year of data.
Example: Stock Price Prediction
Predicting future stock prices based on historical market data.
A complex task due to market volatility, but RNNs can capture trends.

Example: Weather Forecasting
Forecasting weather patterns based on past meteorological data.
While complex, RNNs can identify subtle temporal dependencies.

Example: Predicting Passenger Traffic
Predicting daily traveler numbers at a train station.
RNNs can learn seasonality (weekdays vs. weekends, holidays).
Requires sufficient historical data to capture these patterns.

What is Natural Language Processing?
The interaction between computers and human (natural) language.
Enables computers to understand, interpret, and generate human language.

Character vs. Word-Level Models
Character-Level Models:
- Process text one character at a time.
- Can handle out-of-vocabulary words and typos.
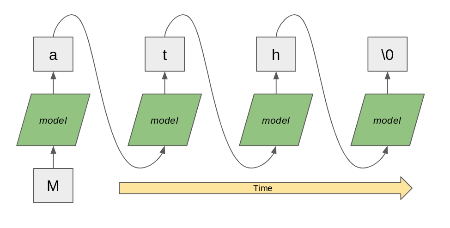
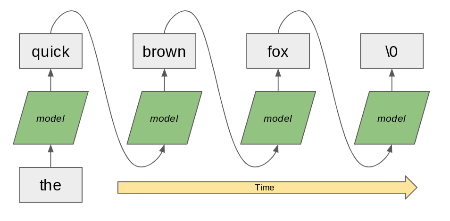
Character vs. Word-Level Models (Cont.)
Word-Level Models:
- Process text one word at a time.
- More common for English and similar languages.
- Often faster to train and perform well.
Which is better? Depends on the language and use case.
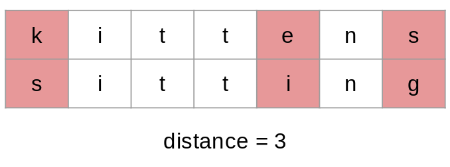
Text Processing: Minimum Edit Distance
Also known as Levenshtein distance.
- Measures the minimum number of single-character edits (insertions, deletions, substitutions) required to change one string into another.
- Crucial for autocorrect, spell checkers, and evaluating text generation systems.
Language Modeling: Bag-of-Words
Simplest language modeling approach.
Treats a sentence as an unordered collection of words.
Example: “I love love loved it!” and “I HATED it :-(”
- Meaning can often be inferred without word order.
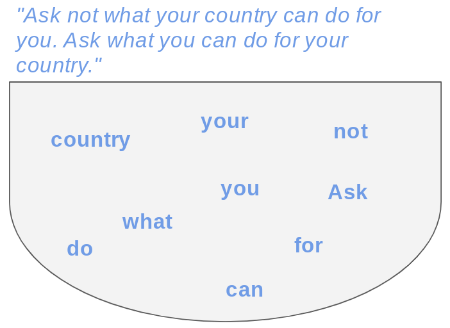
Language Modeling: Sequential Words
While bag-of-words is effective for some tasks (e.g., spam filtering), word order is crucial for complex NLP.
Sequential approaches preserve word order.
This is where Recurrent Neural Networks (RNNs) become indispensable.
